Twitter's Recommendation Algorithm (번역)
트위터 블로그의 다음 글을 번역하였습니다.
트위터는 시시각각 벌어지는 세계 최고의 소식을 여러분에게 전달하고자 노력하고 있습니다. 매일 포스팅되는 약 50억개의 트윗으로부터 유저의 For You 타임라인에 보여줄 트윗을 한 움큼 추려내기 위해서는 추천 알고리즘이 필요합니다. 이 글에서는 알고리즘이 유저들의 타임라인에 보여줄 트윗을 어떻게 골라내는지에 대해 설명합니다.
추천시스템은 앞으로 자세하게 설명할, 여러 상호 연결 서비스 및 작업들로 구성되어있습니다. 트윗들은 검색, 탐색, 광고 등 앱의 여러 지면을 통해 추천되고 있지만 이 글에서는 홈 타임라인의 For You 피드만 다루고자 합니다.
우리는 트윗을 어떻게 고르는가?
트위터의 추천은 트윗, 유저, 그리고 참여(engagement) 데이터로부터 숨겨진 정보를 추출할 수 있는 핵심 모델 및 피처들을 토대로 이루어져 있습니다. 이 모델들은 “당신이 미래에 다른 유저와 상호작용할 확률은 얼마인가?” 또는 “트위터의 커뮤니티란 무엇이고 그들의 트윗 트랜드는 무엇인가?”와 같은 트위터 네트워크에 관한 중요한 질문에 답변하는 것을 지향합니다. 이러한 질문들에 대한 답은 트위터가 더 관련성 높은 추천을 제공할 수 있도록 합니다.
추천 파이프라인은 다음과 같은 기능을 가진 3가지의 메인 스테이지로 이루어져 있습니다.
- Candidate Sourcing
- 서로 다른 추천 소스으로부터 최고의 트윗들을 가져옵니다.
- Rank
- 머신러닝 모델을 사용하여 각 트윗에 대한 랭킹을 매깁니다.
- Heuristics and filters
- 유저가 차단했거나, 불건전한 컨텐츠 또는 유저가 이미 본 트윗들을 필터링합니다.
For You 타임라인을 구성하고 서빙하는 서비스를 Home Mixer라고 부릅니다. Home Mixer는 Product Mixer라 불리는, 컨텐츠 피드 생성을 촉진하는, 자체 제작 scala framework로 만들어져 있습니다. 이 서비스는 서로 다른 candidate source들, scoring 함수, heuristics 및 필터링 사이를 연결하는 중추 소프트웨어 역할을 합니다.
아래의 다이어그램은 타임라인 생성에 사용되는 주요 컴포넌트들을 도식화한 것 입니다.
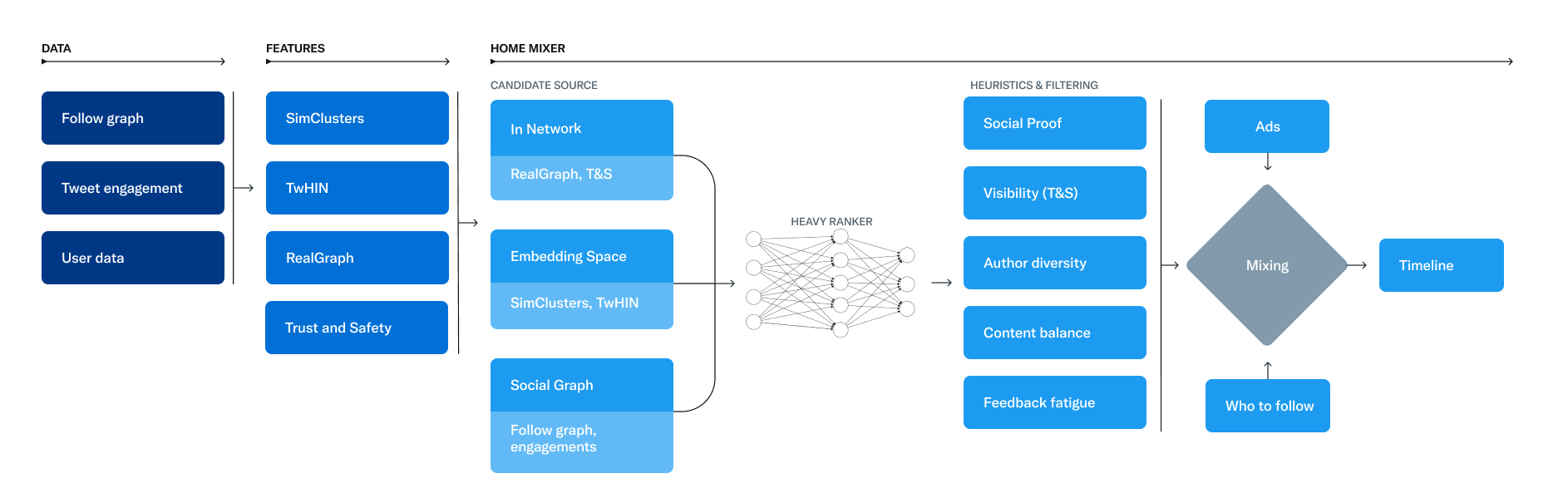
Candidate source로부터 후보를 검색하는 것을 시작으로 타임라인 요청이 들어왔을 때 호출되는 순서대로 이 시스템의 주요한 부분들을 살펴보겠습니다.
Candidiate Sources
트위터는 유저가 최근 관련 높은 트윗을 검색하는데 사용하는 여러 candidate source들을 가지고 있습니다. 이런 소스를 통해 각 요청마다 수십억 개의 후보 중 1500개의 좋은 트윗을 찾아내려고 합니다. 우리는 당신이 팔로우한 사람들(in-network)과 그렇지 않은 사람들(out-of-network)로부터 후보를 찾아낼 수 있습니다. 유저마다 조금씩 다르겠지만, 오늘날 당신의 타임라인은 평균적으로 50%의 In-Network 트윗과 50%의 Out-of-Network 트윗으로 구성되어 있습니다.
In-Network Source
In-Network source는 가장 큰 후보군이며, 당신이 팔로우하는 유저들로부터 가장 관련성 높고 최신의 트윗들을 전달하는 것을 목표로 합니다. Logistic regression model을 이용하면 당신이 팔로우하는 사람들의 트윗을 그들의 탐색에 기반해 효과적으로 순위를 매길 수 있습니다. 이후 가장 좋은 트윗들을 다음 스테이지로 전달합니다.
In-Network 트윗들의 랭킹을 매길 때 가장 중요한 컴포넌트는 Real Graph입니다.
Real Graph는 두 유저 사이의 참여(engagement, ex: like etc…) 우도를 예측하는 모델입니다. Real Graph에서 당신과 트윗 작성자 사이의 점수가 높을수록 그 작성자의 트윗들을 더 많이 포함시킬 것입니다.
In-Network source는 트위터에서 가장 최근까지 작업하던 과제입니다. 우리는 최근에 12년씩이나 된, 각 유저에게 캐시된 트윗으로부터 In-Network 트윗을 제공하는 용도로 사용하던 Fanout 서비스를 종료하였습니다. 우리는 또한 업데이트 및 학습이 진행된지 수년이 지난 logistic regression ranking 모델을 새로 디자인하고 있습니다.
Out-of-Network Sources
유저 네트워크 바깥에서 관련성 높은 트윗을 찾아 내는 것은 매우 까다로운 문제입니다. “당신이 팔로우하지도 않는 작성자라면, 그 트윗이 어떻게 당신과 관련 있다고 말할 수 있습니까?” 트위터는 이 문제를 해결하기 위해 두가지 방식으로 접근했습니다.
Social Graph
첫번째 접근 방식은, 당신이 팔로우하는 사람들의 참여 또는 그들과 유사한 선호를 분석하여 당신이 찾고자하는 관심사를 측정하는 것입니다.
Engagement graph 순회를 통해 다음 질문에 답할 수 있었습니다.
- 내가 팔로우한 사람들이 최근에 참여(engagement)한 트윗들은 무엇인가?
- 나와 비슷한 트윗을 좋아하는 사람들이 최근에 좋아한 트윗들은 무엇인까?
우리는 이러한 질문에 대한 답변을 토대로 트윗 후보군을 생성하고, logistic regression model을 사용하여 트윗들의 순위를 매겼습니다. 우리는 유저와 트윗 간의 실시간 상호작용 그래프를 유지하는 그래프 처리 엔진인 GraphJet를 개발했으며, 이러한 유형의 Graph 순회는 Out-of-Network 추천에 필수적입니다.
트위터 참여(engagement) 및 팔로우 네트워크를 탐색하는 이런 경험적 방법은 유용성이 입증되었지만(현재 홈 타임라인의 약 15% 제공), embedding space 접근 방식이 Out-of-Network 트윗들의 대부분을 차지하고 있습니다.
Embedding Spaces
Embedding space 접근 방식은 컨텐츠 유사도에 관한 더 일반적인 질문에 대해 답하는 것을 목표로 합니다: “어떤 트윗과 유저가 나의 기호와 비슷할까?”
Embedding은 유저 기호와 트윗 컨텐츠의 numerical representation(=벡터)을 생성함으로써 작동합니다. 그리고나면 우리는 embedding space 위에서 두 유저, 두 트윗, 혹은 유저-트윗 사이의 유사도를 계산할 수 있습니다. 정확한 embedding을 제공할 수만 있으면, 이 유사도를 관련성의 척도로 사용할 수 있습니다.
트위터에서 가장 유용한 embedding space는 SimClusters입니다.
SimClusters는 직접 제작한 matrix factorization(행렬 분해) 알고리즘을 이용하여 인플루언서 유저의 클러스터를 고정했을 때의 커뮤니티들을 탐색합니다. 매 3주마다 145,000 개의 커뮤니티들이 업데이트되고 있습니다. 이러한 커뮤니티 공간에서 유저와 트윗은 커뮤니티 공간에 표현되고, 여러 커뮤니티에 속하는 것도 가능합니다. 커뮤니티의 크기는 친구들로 구성된 몇 천 명부터, 뉴스 또는 팝문화의 수십 억 명까지입니다. 가장 큰 커뮤니티들은 다음과 같습니다.
- Pop
- News
- NBA
- Soccer
- Bollywood
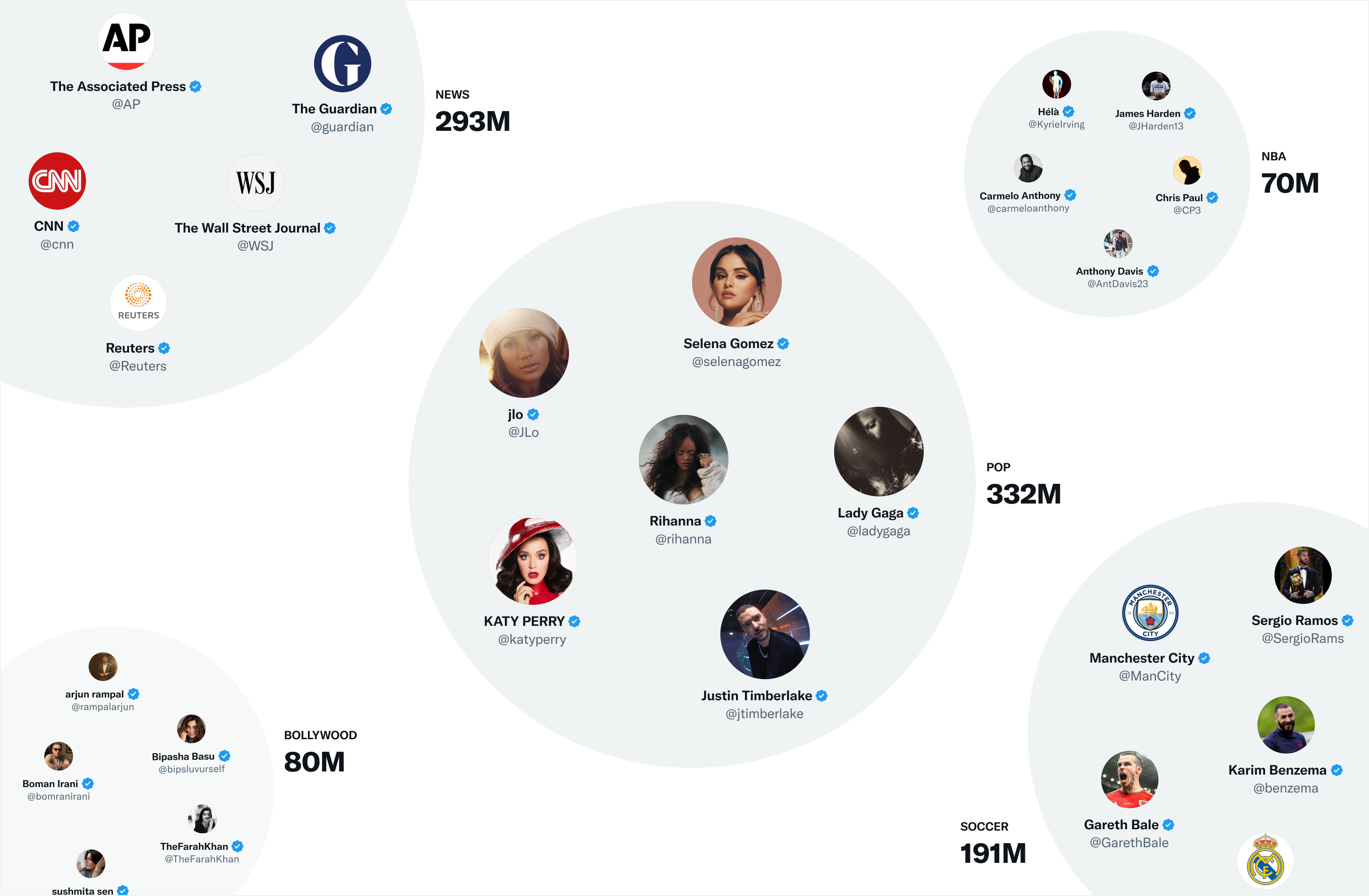
각 커뮤니티 마다 현재 가장 인기있는 트윗을 찾음으로써 트윗들을 커뮤니티에 임베딩할 수 있습니다. 한 커뮤니티의 유저들이 트윗에 더 많은 좋아요를 날릴 수록 그 트윗과 해당 커뮤니티 사이의 관련성은 커지게 됩니다.
Ranking
For You 타임라인의 목적은 관련성 높은 트윗을 당신에게 제공하는 것입니다. 파이프라인 관점에서, 우리는 관련성 높은 1500개의 후보를 얻을 수 있습니다. 점수를 매기는 것은 각 후보 트윗의 관련성을 측정하는것이며, 당신의 타임라인에서 트윗의 순위를 부여하는 주요한 시그널입니다. 이 스테이지에서는 모든 추천 후보가 그것의 source가 어디였든지 간에 동등하게 다루어집니다.
Ranking은 긍정적 참여(Like, Retweet, Reply)를 최적화하기 위해 트윗 상호작용을 지속적으로 학습하는 48M개의 parameter를 가진 신경망(neural network)를 갖고 있습니다. 이 랭킹 매커니즘은 수 천개의 피처를 고려하여 각 트윗마다 점수를 매기기 위한, 참여(engagement) 확률을 의미하는 10개의 라벨을 출력합니다. 우리는 이 점수를 토대로 트윗의 순위를 매깁니다.
Heuristics, Filters, and Product Features
Ranking 스테이지를 지나면, 우리는 다양한 상품 피처를 구현하기 위해 heuristic과 filter을 적용합니다. 이 피처들은 균형있고 다양한 피드를 생성하기 위해 협력합니다. 몇몇 예시들 입니다:
- Visibility Filtering
- 트윗의 컨텐츠나 유저의 선호에 따라 트윗을 필터링합니다. 예를들어 당신이 차단 또는 음소거한 계정의 트윗은 제거됩니다.
- Author Diversity
- 동일한 사람이 작성한 트윗이 너무 많아지거나 연속되는 경우는 피합니다.
- Content Balance
- In-Network와 Out-of-Netowrk 트윗의 균형을 조절합니다.
- Feedback-based Fatigue
- 부정적인 피드백을 받은 트윗들은 점수를 낮게 줍니다.
- Social Proof
- 품질 유지를 위해 2촌 이내의 연결이 아닌 Out-of-Network 트윗들은 제거합니다. 즉, 당신이 팔로우하는 사람이 그 트윗에 참여했거나 트윗의 작성자를 팔로우 해야합니다.
- Conversations
- 답글을 원래 트윗과 함께 스레딩함으로써 더 많은 컨텍스트를 제공합니다.
- Edited Tweets
- 현재 기기에 있는 트윗이 오래된 것인지 확인하고 수정된 버전으로 교체하라는 명령을 내립니다.
Mixing and Serving
이 지점에서 Home Mixer는 트윗들을 당신의 기기로 보낼 준비가 되었습니다. 마지막 처리 과정에서 시스템은 당신의 화면에 보여질 트윗 및 트윗이 아닌 컨텐츠, 예를 들면 광고, 팔로우 추천, 온보딩 프롬프트를 섞습니다.
위의 파이프라인은 하루에 거의 500만 번 실행되며 평균 1.5초 안에 완료됩니다. 단일 파이프라인 실행에는 220초 정도의 CPU 시간이 필요하며 이는 앱에서 인식하는 대기 시간의 150배에 달합니다.
오픈 소스를 공개하는 목적은, 시스템 작동 방식에 관해 사용자에게 완전한 투명성을 제공하는 것입니다. 우리는 알고리즘에 대한 자세한 이해를 돕기 위해 우리의 추천 코드를 볼 수 있도록 배포했으며 앱 내에서 더 큰 투명성을 제공하기 위해 여러 기능들을 작업하고 있습니다.
우리가 계획한 새로운 개발 중 일부는 다음과 같습니다.
- 달성(reach)과 참여(engagement) 정보를 제공하는, 크리에이터를 위한 더 나은 트위터 분석 플랫폼
- 트윗 또는 계정에 적용된 모든 안전 라벨에 대한 투명성 향상
- 타임라인에 트윗이 표시되는 이유에 대한 가시성 향상
앞으로는?
트위터는 전 세계 대화의 중심입니다. 매일 사람들의 장치에 1500억 개 이상의 트윗을 제공하고 있습니다. 유저에게 가능한 한 최고의 컨텐츠를 제공하는 것은 어려우면서도 흥미로운 문제입니다. 우리는 새로운 실시간 기능, 임베딩 및 유저 벡터와 같은 추천 시스템을 확장할 수 있는 새로운 기회를 위해 노력하고 있으며 이를 수행할 수 있는 세계에서 가장 흥미로운 데이터 세트 및 사용자 층을 보유하고 있습니다. 우리는 미래의 마을 광장을 건설하고 있습니다. 관심이 있다면 합류를 고민해 보시길 바랍니다.