Trino Gateway를 한번만 알아보자
Trino란?
Trino는 대용량 데이터 셋을 여러 서버에 걸쳐 병렬로 처리하기 위한 분산 쿼리 엔진으로, HDFS 뿐만 아니라 MySQL, Kafka, Cassandra 등 다양한 종류의 데이터 소스를 지원하여 많은 사람들에게 사랑받고 있는 오픈 소스이다.
Trino Cluster는 하나의 Coordinator와 복수의 Workers로 구성되어 있는데, 사용자가 쿼리를 날리면 Coordinator가 전달 받은 SQL를 분석하여 실행 계획을 세운다. 그러면 Worker들이 실행 계획에 따라 작업을 수행하고 그 결과를 Coordinator를 통해 사용자에게 전달한다.
일단 작업이 시작되면 하나의 쿼리는 여러 Stage로 나뉘어 순차적으로 실행되며 Coordinator는 Worker들과의 API 통신을 통해 작업 경과를 보고 받는다. 또한 Spark 처럼 “Shuffle”을 위해 Worker들끼리 통신을 하기도 한다.
Trino의 아키텍처와 동작 방식과 관련해서는 2023 Naver Deview에서 발표된 적이 있다.
Trino Gateway란?
Trino Gateway는 다수의 Trino Cluster를 운영하고 있을 때 Load Balancer 및 Routing Gateway의 역할을 목적으로 사용된다. 기존에 수 많은 클러스터의 URL과 Credential을 각각 관리하는 대신 사용자에게 하나의 URL만 제공하고 Rest API를 이용해 필요한 규칙들을 손쉽게 구성할 수 있다.
Trino Gateway 또한 Trino와 마찬가지로 Presto Gateway로부터 fork되어 리팩토링되었으며, 오픈소스이기 때문에 Github에서 찾아볼 수 있다.
이름에서 유추할 수 있듯이 다음과 같은 목적으로 사용된다.
1. Routing
분석 환경을 굳이 구분하자면, 적시적인 데이터 분석을 위해 상시로 쿼리가 실행되는 “Adhoc” 환경과 데이터 마트 또는 머신러닝을 위해 배포된 파이프라인이 실행되는 “Production” 환경 두 가지가 있을 수 있다.
두 개발 환경 모두가 같은 Trino Cluster를 사용하는 상황이라면 특정 시간에 스케쥴링된 Production 환경의 작업들이 Adhoc하게 실행되는 쿼리들로 인해 방해 받을 수 있다.
이를 방지하기 위해서는 두 개 이상의 클러스터를 운영하여 각 환경이 목적에 맞는 Trino 서버에 접근할 수 있도록 분리하는 것이 좋다. 이때 Trino Gateway를 사용하면 사용자들에게는 하나의 URL만 제공하되, 환경 별로 혹은 사용자 별로 연결을 통제할 수 있기 때문에 관리에 용이하다.
2. Blue / Green Deployment
Trino Cluster를 사용하고 있다면 온디맨드 서비스를 제공하기 위해 서버가 상시적으로 띄워져 있을 가능성이 높다.
여기서 만약 클러스터를 업그레이드 하거나 새로운 노드로 교체하고자 한다면 Trino Gateway를 이용해 Blue / Green 배포가 가능하다. 새로운 클러스터 서버를 띄운 후 API를 통해 Trino Gateway에서 교체하고자 하는 서버와 같은 Routing Group에 등록해주면 된다.
클러스터가 Trino Gateway에 등록된 이후에도 API를 통해 해당 클러스터의 Routing Group을 변경하거나 비활성화를 위해 Graceful Shutdown 시키는 것이 가능하다.
Let’s Practice
다음 Github 링크에 상세한 설정을 정리해 두었습니다.
현업에서 Trino Gateway를 도입해야할 만큼 여러 클러스터를 운영해 볼 기회는 극히 드물다. 따라서 Docker를 이용해 서버를 띄워보고 “아 이런게 있구나!” 정도로만 실습해보려 한다. Trino Gateway를 띄우려면 다수의 Trino Cluster가 필요하고, Trino Cluster를 띄우기 위해서는 데이터가 저장될 Object Storage와 Hive Metastore를 세팅해야 한다.
전체적인 시스템 디자인을 그려보면 다음과 같다.
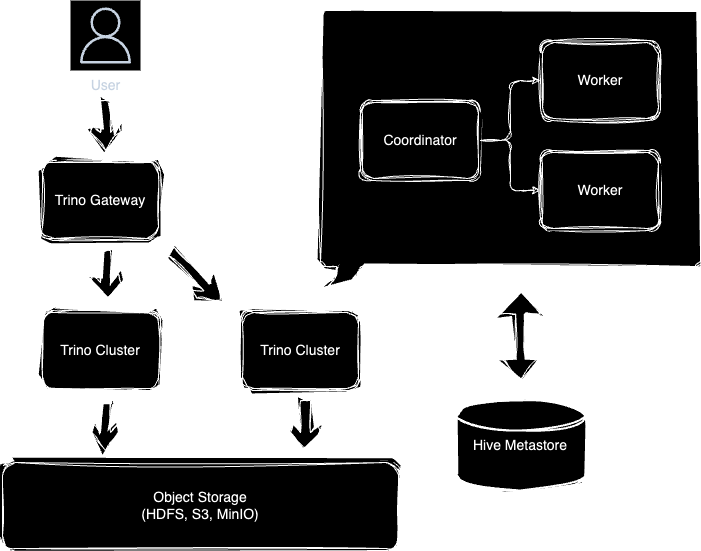
1. Trino
먼저 데이터가 저장될 Object Storage를 구성해야 한다. 흔히 사용되는 AWS S3 대신에 오픈소스인 MinIO를 선택하였다.
1
2
3
4
5
6
7
8
9
10
11
12
minio:
container_name: minio
hostname: minio
image: minio/minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_DOMAIN: minio
command: server /data --console-address ":9001"
다음은 관계형 데이터베이스인 Postgres이다. 편의를 위해서 Hive Metastore 및 Trino Gateway의 백엔드 역할을 동시에 수행하도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
postgres:
container_name: postgres
hostname: postgres
image: postgres:14-alpine
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- ./docker/volume/postgres:/var/lib/postgresql/data
- ./docker/postgres/init-database.sh:/docker-entrypoint-initdb.d/init-database.sh
다음으로는 Trino가 테이블 및 파티션 정보를 저장하고 조회할 Hive Metastore를 구성한다. Starburst의 도커 이미지를 사용하면 .env 파일에 S3 엔드포인트와 Postgres 서버 정보를 환경 변수에 등록하여 Hive Metastore가 접근할 수 있도록 설정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
hive-metastore:
container_name: hive-metastore
hostname: hive-metastore
image: starburstdata/hive:3.1.3-e.6
ports:
- "9083:9083"
env_file:
- ./docker/hive-metastore/.env
depends_on:
- postgres
- minio
마지막으로 1개의 Coordinator와 2개의 Worker로 구성된 Trino Cluster를 세팅한다. Coordinator와 Worker는 동일한 도커 이미지를 사용하되 config.properties 파일을 서로 다르게 구성하여 volume에 마운트하면 된다. 이 때 config.properties 파일 속 설정에 대해서는 반드시 알아야 할 것들이 많으므로 공식 문서를 읽어보는 것이 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
trino-1:
container_name: trino-1
hostname: trino
image: trinodb/trino:435
ports:
- "8081:8080"
volumes:
- ./docker/trino/etc-coordinator:/etc/trino
- ./docker/trino/catalog:/etc/trino/catalog
depends_on:
- hive-metastore
trino-1-worker-1:
container_name: trino-1-worker-1
hostname: trino-worker-1
image: trinodb/trino:435
ports:
- "8082:8080"
volumes:
- ./docker/trino/etc-worker:/etc/trino
- ./docker/trino/catalog:/etc/trino/catalog
depends_on:
- trino-1
trino-1-worker-2:
container_name: trino-1-worker-2
hostname: trino-worker-2
image: trinodb/trino:435
ports:
- "8083:8080"
volumes:
- ./docker/trino/etc-worker:/etc/trino
- ./docker/trino/catalog:/etc/trino/catalog
depends_on:
- trino-1
2. Trino Gateway
Trino Gateway 서버는 JVM 기반으로 작동한다. Maven에 등록된 JAR 파일을 다운로드 받은 후 서버를 실행 시킨 뒤, 3개의 port를 열어주어야 한다. 이 때 gateway-config.yaml 파일에는 백엔드로 사용할 Postgres 서버 정보를 입력해 주면 된다.
[Dockerfile]
1
2
3
4
5
6
7
8
9
10
FROM openjdk:17-jdk-slim
WORKDIR /etc/trino-gateway
RUN apt-get -y update && apt-get -y install curl
ARG VERSION
ARG JAR_FILE
RUN curl https://repo1.maven.org/maven2/io/trino/gateway/gateway-ha/${VERSION}/gateway-ha-${VERSION}-jar-with-dependencies.jar -o ${JAR_FILE}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
trino-gateway:
container_name: trino-gateway
hostname: trino-gateway
build:
args:
VERSION: 4
JAR_FILE: gateway-ha.jar
dockerfile: ./docker/trino-gateway/Dockerfile
image: trino-gateway
ports:
- "9080:9080"
- "9081:9081"
- "9082:9082"
volumes:
- ./docker/trino-gateway/gateway-config.yaml:/etc/trino-gateway/gateway-config.yaml
- ./docker/trino-gateway/routing-rule.yaml:/etc/trino-gateway/routing-rule.yaml
depends_on:
- postgres
entrypoint: [
"java",
"--add-opens=java.base/java.lang=ALL-UNNAMED",
"--add-opens=java.base/java.net=ALL-UNNAMED",
"-jar", "gateway-ha.jar",
"server", "gateway-config.yaml"
]
Docker compose 실행에 필요한 yaml 파일이 준비되었다면 다음 명령어를 통해 컨테이너들을 생성할 수 있다.
1
dodcker compose up # 또는 docker-compose up
3. Rest API
Trino Cluster와 Trino Gateway 서버가 무사히 띄워진 후에는 Rest API를 이용해 클러스터를 서버에 등록할 수 있다. 또 query parameter를 조작하여 등록과 삭제가 가능하며 등록한 Trino Cluster를 비활성화 시키는 것도 가능하다.
[register-trino-1.json]
1
2
3
4
5
6
7
{
"name": "trino-1",
"proxyTo": "http://trino-1:8080",
"active": true,
"externalUrl": "http://localhost:8081",
"routingGroup": "adhoc"
}
1
2
3
curl -H "Content-Type: application/json" \
-X POST localhost:9080/gateway/backend/modify/update \
-d @scripts/register-trino-1.json
웹 서버(http://localhost:9080/viewgateway)로 접속하면 등록된 클러스터를 확인할 수 있다.
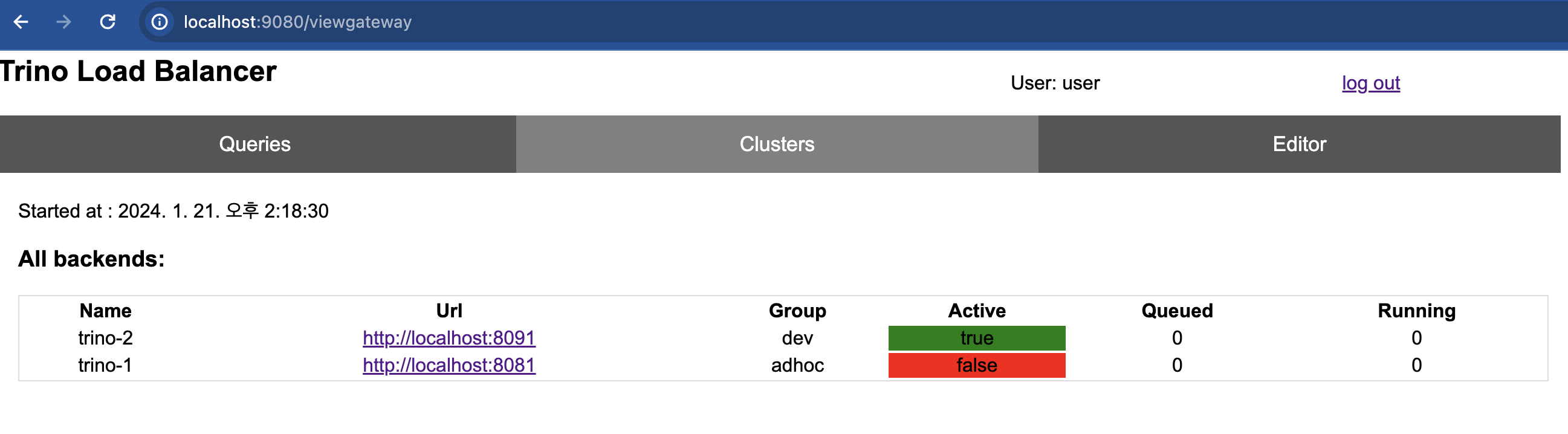
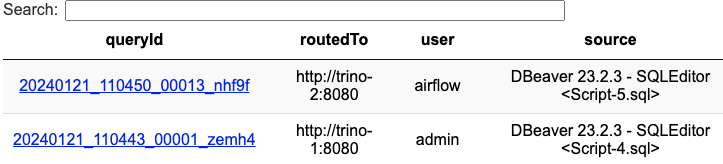
앞서 설명한대로 Routing Rule을 구성하면 사용자 별로 서로 다른 클러스터로 라우팅할 수 있다. 예를 들어 “airflow” 라는 계정으로 SQL을 날리면 Routing Group이 “etl”인 클러스터에서 쿼리가 실행되도록 할 수 있다. 또한 yaml 파일만 수정하면 서버를 내리지 않고도 언제든지 라우팅 룰을 추가 및 변경할 수 있다.
[routing-rule.yaml]
1
2
3
4
5
name: "airflow"
description: "if query from airflow, route to etl group"
condition: 'request.getHeader("X-Trino-User") == "airflow"'
actions:
- 'result.put("routingGroup", "etl")'
Trino UI(http://localhost:8080/ui)에서 쿼리 내역을 살펴보면 “admin” 유저는 “trino-1” 클러스터로, “airflow” 유저는 “trino-2” 클러스터로 라우팅되었음을 확인할 수 있다.