How we built Text-to-SQL at Pinterest (번역)
미디엄의 다음 글을 번역하였습니다.
분석 문제를 해결하는데 있어서 쿼리를 작성하는 것은 Pinterest의 데이터 사용자에겐 매우 중요한 작업입니다. 하지만 올바른 데이터를 찾거나 분석 문제를 정확하고 효율적인 SQL로 변환하는 것은 어려운 작업일 수 있습니다. 특히 빠르게 변화하는 환경에서 서로 다른 도메인에 흩어져 있는 상당한 양의 데이터를 처리해야 하는 경우에는 더더욱이요.
우리는 이러한 분석 질문을 코드로 변환해주는 Text-to-SQL 기능을 개발함으로써, LLM(대형 언어 모델)의 가용성 향상이 데이터 사용자의 작업에 도움이 될지 알아 볼 기회를 가질 수 있었습니다.
Pinterest에서 Text-to-SQL이 작동하는 방식
Pinterest에서는 대부분의 데이터 분석이 사내 오픈소스 빅데이터 SQL 쿼리 도구인 Querybook에서 이루어집니다. 이곳은 Text-to-SQL를 포함하여 데이터 사용자를 지원하는 새로운 기능들을 개발하고 배포하기에 최적의 환경입니다.
Text-to-SQL 구현
초기 버전 - LLM을 활용한 Text-to-SQL
첫 번째 버전은 LLM을 활용한, 간단한 Text-to-SQL 솔루션입니다. 아키텍처를 자세히 살펴보겠습니다.
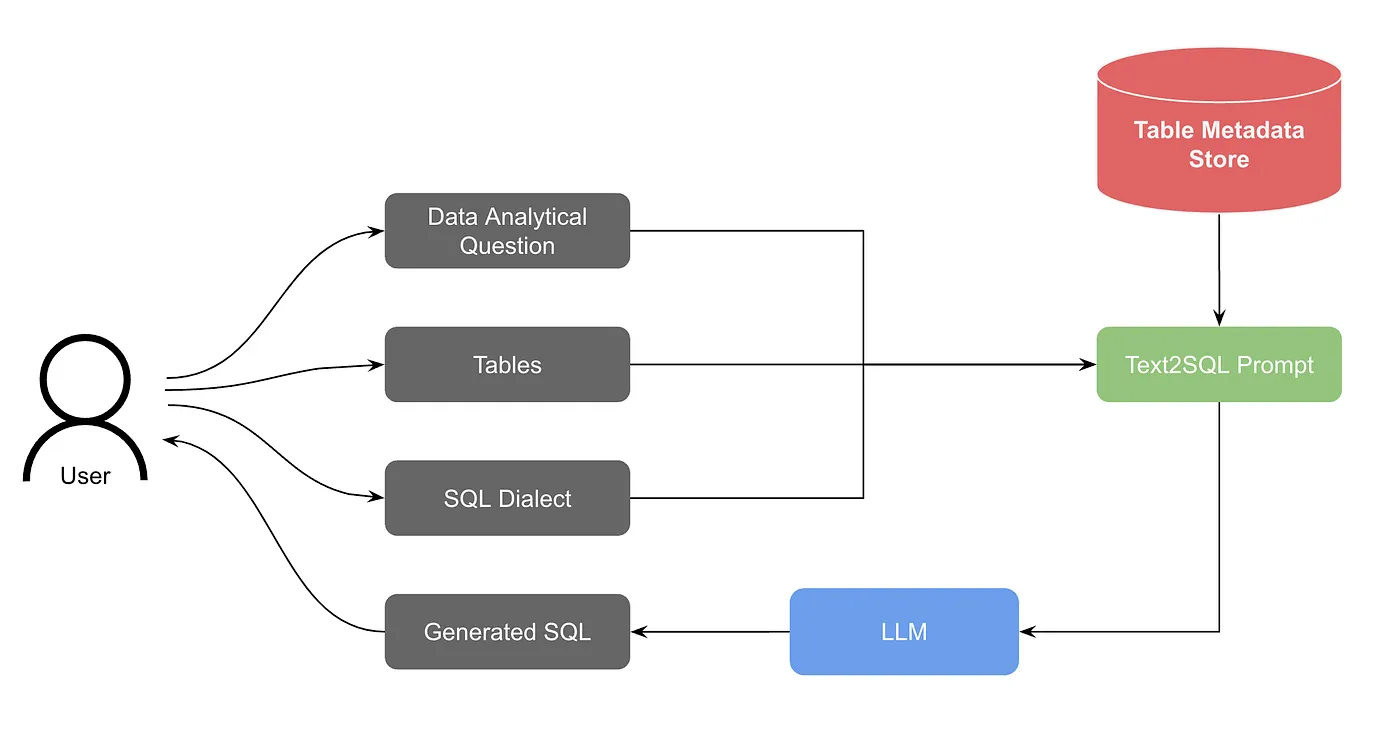
유저는 사용할 테이블들을 선택하고 분석 질문을 던집니다.
- 테이블 메타데이터 저장소에서 관련 테이블 스키마가 검색됩니다.
- 분석 질문 및 SQL dialect, 그리고 테이블 스키마가 Text-to-SQL 프롬프트로 컴파일됩니다.
- LLM에 프롬프트를 제출합니다.
- 스트리밍 응답이 생성되어 사용자에게 표시됩니다.
테이블 스키마
메타데이터 저장소에서 가져온 테이블 스키마에는 다음과 같은 요소들이 포함되어 있습니다.
- Table name
- Table description
- Columns
- Column name
- Column type
- Column description
Low-Cardinality 컬럼
“웹 플랫폼에는 얼마나 많은 활성 사용자가 있습니까?” 처럼 모호한 분석 질문을 던진다면 데이터베이스의 실제값과는 다른 SQL 쿼리 응답이 생성될 가능성이 있습니다.
예를 들어 올바른 WHERE platform='WEB' 대신 WHERE platform='web'이 응답의 where 절에 포함될 수 있습니다.
이러한 문제를 해결하기 위해서는 낮은 cardinality의 컬럼이 필터링에 사용되는 경우, LLM이 정확한 SQL 쿼리를 생성할 수 있도록 컬럼의 고유값들을 테이블 스키마에 포함시켜 주어야 합니다.
Context Window 제한
테이블 스키마가 너무 클때에는 context window 제한을 초과할 수도 있습니다. 이 문제를 해결하기 위해 우리는 몇 가지 기술들을 적용하였습니다.
- 테이블 스키마 축소: 테이블 이름, 컬럼 이름 및 타입 등 중요한 요소들만 포함시킵니다.
- 컬럼 가지치기: 메타데이터 저장소에서 각 컬럼에 태그를 붙이고, 해당 태그를 기반으로 테이블 스키마에서 특정 컬럼을 제외합니다.
Response Streaming
LLM이 응답하는데는 수십 초가 걸릴 수 있으므로 사용자가 기다릴 필요가 없도록 WebSocket을 사용하여 응답을 스트리밍했습니다. 만약 생성된 SQL 이외에도 다양한 정보를 반환해야 하는 요구 사항이 있다면, 응답 형식을 적절하게 구조화하는 것이 중요합니다.
Plain text는 스트리밍하기가 간단한 반면, JSON 스트리밍은 비교적 까다로울 수 있습니다. 우리는 서버 스트리밍을 위해 Langchain의 JSON parser를 채택하였으며, 이렇게 파싱된 JSON은 WebSocket을 통해 클라이언트로 다시 전송됩니다.
프롬프트
Text2SQL에 현재 사용하고 있는 프롬프트 는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from langchain.prompts import PromptTemplate
prompt_template = """
You are a {dialect} expert.
Please help to generate a {dialect} query to answer the question. Your response should ONLY be based on the given context and follow the response guidelines and format instructions.
===Tables
{table_schemas}
===Original Query
{original_query}
===Response Guidelines
1. If the provided context is sufficient, please generate a valid query without any explanations for the question. The query should start with a comment containing the question being asked.
2. If the provided context is insufficient, please explain why it can't be generated.
3. Please use the most relevant table(s).
5. Please format the query before responding.
6. Please always respond with a valid well-formed JSON object with the following format
===Response Format
{
"query": "A generated SQL query when context is sufficient.",
"explanation": "An explanation of failing to generate the query."
}
===Question
{question}
"""
TEXT_TO_SQL_PROMPT = PromptTemplate.from_template(prompt_template)
평가 및 학습
Text-to-SQL의 초기 성능 평가에서는 구현의 대부분이 기존의 접근 방식을 차용했다는 점을 고려하여 구현이 문헌에 보고된 결과와 비슷한 성능을 갖는지 확인하는 방식으로 수행되었습니다.
우리는 Spider Dataset을 사용해 다른 곳에서 발표된 결과와 유사한 결과를 얻었습니다. 하지만 이 벤치마크 속 실험들은 유저가 실제로 풀어야할 문제보다 훨씬 쉽습니다. 특히 잘 라벨링된 컬럼과 함께 사전에 지정된 소수의 테이블만을 고려하고 있다는 점을 유의해야 합니다.
Text-to-SQL 솔루션이 프로덕션에 배포된 후에는 사용자가 시스템과 상호 작용하는 방식도 관찰할 수 있었습니다. 구현이 개선되고 사용자가 이 기능에 더 익숙해짐에 따라 생성된 SQL이 한번에 채택되는 비율이 20%에서 40% 이상으로 증가했습니다. 실제로는 생성된 쿼리의 대부분은 완성되기까지 인간 또는 AI에 의한 생성을 여러 번 반복해야 합니다.
Text-to-SQL이 데이터 사용자의 생산성에 얼마나 영향을 미치는지 확인할 수 있는 가장 신뢰가능한 방법은 실험이었습니다. 이전 연구에서는 AI assistance가 작업 속도를 50% 이상 향상시키는 것으로 나타났습니다. (과제 간 다름을 심각하게 제어하지 않은) 우리의 실제 데이터 기반 실험에서 AI assistance를 사용하여 SQL 쿼리를 작성할 때 작업 속도가 35% 향상된 것으로 나타났습니다.
개선 버전 - RAG를 활용한 Table Selection
첫 번째 버전은 사용자가 자신이 사용할 테이블을 알고 있다고 가정할 때 괜찮은 성능을 발휘하지만, 실제로 데이터 웨어하우스에 있는 수십만 개의 테이블 중에서 적절한 테이블을 찾아내는 것은 사용자에게 매우 어려운 일입니다.
이를 완화하기 위해 RAG(Retrieval Augmented Generation)를 통합하여 사용자가 작업에 필요한 테이블을 선택할 수 있도록 안내했습니다. RAG가 추가된 새로운 인프라 구조를 살펴보자면 다음과 같습니다.

- 테이블 summary 및 테이블 사용 쿼리의 벡터 인덱스를 생성하기 위해 오프라인 작업을 수행합니다.
- 사용자가 테이블을 지정하지 않으면 질문이 임베딩으로 변환되고, 벡터 인덱스에 대해 Similarity Search를 수행하여 관련성이 높은 상위 N개의 테이블을 추론합니다.
- 상위 N 테이블은 테이블 스키마 및 분석 질문과 함께 가장 관련성이 높은 상위 K 테이블을 선택하라는 프롬프트로 컴파일되어 LLM에게 넘어갑니다.
- 검증 또는 변경을 위해 상위 K개 테이블이 사용자에게 반환됩니다.
- 사용자가 확인한 테이블을 사용하여 표준 Text-to-SQL 프로세스가 재개됩니다.
오프라인 벡터 인덱스 생성
벡터 인덱스에는 두 가지 유형의 문서 임베딩이 있습니다.
- Table Summarization
- Query Summarization
Table Summarization
Pinterest에서는 테이블에 tier를 붙이기 위한 테이블 표준화 작업이 진행 중 입니다. 우리는 탑 티어 테이블만 인덱싱하여 고품질 데이터 세트가 사용될 수 있도록 장려하고 있습니다. 다음 과정을 통해 테이블 요약 생성 프로세스가 진행됩니다.
- 테이블 메타데이터 저장소에서 테이블 스키마를 검색합니다.
- 테이블의 가장 최근의 샘플 쿼리를 수집합니다.
- Context window를 기반으로 테이블 요약 프롬프트에 테이블 스키마와 함께 가능한 한 많은 샘플 쿼리를 합칩니다.
- 요약을 생성하기 위해 프롬프트를 LLM에 전달합니다.
- 벡터 저장소에 임베딩을 생성하고 저장합니다.
Table summary에는 테이블에 대한 설명, 담고 있는 데이터 및 잠재적인 사용 시나리오가 포함됩니다. 다음은 현재 table summary에 사용하고 있는 프롬프트입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from langchain import PromptTemplate
prompt_template = """
You are a data analyst that can help summarize SQL tables.
Summarize below table by the given context.
===Table Schema
{table_schema}
===Sample Queries
{sample_queries}
===Response guideline
- You shall write the summary based only on provided information.
- Note that above sampled queries are only small sample of queries and thus not all possible use of tables are represented, and only some columns in the table are used.
- Do not use any adjective to describe the table. For example, the importance of the table, its comprehensiveness or if it is crucial, or who may be using it. For example, you can say that a table contains certain types of data, but you cannot say that the table contains a 'wealth' of data, or that it is 'comprehensive'.
- Do not mention about the sampled query. Only talk objectively about the type of data the table contains and its possible utilities.
- Please also include some potential usecases of the table, e.g. what kind of questions can be answered by the table, what kind of analysis can be done by the table, etc.
"""
TABLE_SUMMARY_PROMPT = PromptTemplate.from_template(prompt_template)
Query Summarization
Table summary 역할 외에도 각 테이블과 관련된 샘플 쿼리들 또한 요약됩니다. 여기에는 사용되는 테이블과 쿼리의 목적 등의 정보가 포함될 수 있습니다. 이때 사용하는 프롬프트는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from langchain import PromptTemplate
prompt_template = """
You are a helpful assistant that can help document SQL queries.
Please document below SQL query by the given table schemas.
===SQL Query
{query}
===Table Schemas
{table_schemas}
===Response Guidelines
Please provide the following list of descriptions for the query:
-The selected columns and their description
-The input tables of the query and the join pattern
-Query's detailed transformation logic in plain english, and why these transformation are necessary
-The type of filters performed by the query, and why these filters are necessary
-Write very detailed purposes and motives of the query in detail
-Write possible business and functional purposes of the query
"""
SQL_SUMMARY_PROMPT = PromptTemplate.from_template(prompt_template)
NLP 기반 테이블 검색
사용자가 분석 질문을 입력하면 임베딩 모델을 사용하여 이를 임베딩으로 변환합니다. 그런 다음 테이블 및 쿼리 모두에 대해 벡터 인덱스를 사용한 검색을 수행합니다. 우리는 OpenSearch를 벡터 저장소로 사용하고 있으며 내장된 Similarity Search 기능을 사용하고 있습니다.
하나의 쿼리가 여러 테이블과 연관이 있을 수 있음을 고려하면, Similarity Search 결과에서 하나의 테이블이 여러 차례 나타날 수 있습니다. 지금은 query summary 보다 table summary에 더 많은 가중치를 주는 단순한 채점 전략을 사용하고 있지만, 추후에 채점 전략을 조정할 수도 있습니다.
이 NLP 기반 테이블 검색은 Text-to-SQL에서 사용될 뿐만 아니라, Querybook의 테이블 검색 기능에도 사용됩니다.
Table Re-selection
벡터 인덱스로부터 상위 N개의 테이블을 검색한 후, LLM을 사용하여 테이블 요약과 함께 질문을 평가하여 가장 관련성이 높은 K개의 테이블을 재선택합니다. Context window에 따라 프롬프트에 가능한 한 많은 테이블을 추가합니다. 다음은 Table Re-selection에 사용하는 프롬프트입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
from langchain import PromptTemplate
prompt_template = """
You are a data scientist that can help select the most relevant tables for SQL query tasks.
Please select the most relevant table(s) that can be used to generate SQL query for the question.
===Response Guidelines
- Only return the most relevant table(s).
- Return at most {top_n} tables.
- Response should be a valid JSON array of table names which can be parsed by Python json.loads(). For a single table, the format should be ["table_name"].
===Tables
{table_schemas}
===Question
{question}
"""
TABLE_SELECT_PROMPT = PromptTemplate.from_template(prompt_template)
테이블이 재선택되고 나면, SQL 생성 단계로 진입하기 전에 사용자에게 검증을 받기 위한 테이블 목록을 반환합니다.
평가 및 학습
우리는 기존의 테이블 검색 시스템으로부터 오프라인 데이터를 수집하여 Text-to-SQL 시스템의 테이블 검색 기능을 평가하였습니다. 그러나 이 데이터에는 한 가지 치명적인 맹점이 있었는데, NLP 기반 검색이 가능하다는 사실을 알기 전의 사용자 행동을 포착한다는 것이었습니다.
따라서 이 데이터는 개선 정도를 측정하기보다는 임베딩 기반 테이블 검색이 기존 텍스트 기반 검색보다 성능이 떨어지지 않는지 확인하는 목적으로 사용되었습니다.
우리는 이 평가 결과를 테이블 검색에 사용되는 임베딩 방식을 선택하고 가중치를 설정하는데 사용하기로 했습니다. 덕분에 사내 데이터 거버넌스 작업으로부터 생성된 테이블 메타데이터가 전체 성능에 매우 큰 영향을 준다는 사실을 밝힐 수 있었습니다. 테이블 문서화 없이 임베딩한 경우 검색 적중률은 40% 였지만, 테이블 문서화에 가중치를 둘 수록 성능이 90% 까지 선형적으로 증가하였습니다.
향후 과제
현재 구현된 Text-to-SQL은 데이터 분석가의 생산성을 크게 향상시켰지만 여전히 개선의 여지가 있습니다. 추가적으로 개발이 가능한 몇 가지 영역은 다음과 같습니다.
NLP 기반 테이블 검색
- 메타데이터 개선
현재 벡터 인덱스는 table summary에만 적용되어 있습니다만, 유사한 테이블을 검색할 때 티어, 태그, 도메인 등과 같은 메타데이터를 추가적으로 사용하여 더 정교하게 필터링 할 수 있도록 개선 가능합니다.
- Scheduled or Real-Time Index Update
현재 벡터 인덱스는 수동으로 생성됩니다. 새 테이블이 생성되거나 쿼리가 실행될 때마다 예약된 업데이트 또는 실시간 업데이트를 구현하면 시스템 효율성이 향상됩니다.
- Similarity Search and Scoring Strategy Revision
Similarity Search 결과를 집계하는 현재의 채점 전략은 다소 기초적입니다. 이 측면을 미세 조정하면 검색된 결과의 관련성을 향상시킬 수 있습니다.
쿼리 검증
현재 LLM으로 생성된 SQL 쿼리는 유효성 검사 없이 사용자에게 직접 전달되므로, 예상과 다르게 쿼리가 실행되지 않을 위험이 있습니다. 따라서 Constrained Beam Search와 같은 방법을 통해 쿼리 유효성 검사를 할 수 있다면 품질 보증 계층을 제공할 수 있습니다.
유저 피드백
테이블 검색 및 쿼리 생성 결과에 대한 사용자의 피드백을 수집할 수 있는 인터페이스를 도입한다면, 개선을 위한 귀중한 통찰력을 얻을 수 있습니다. 이러한 피드백을 벡터 인덱스나 테이블 메타데이터 저장소에 반영할 수 있다면 궁극적으로 시스템 성능을 향상시킬 수 있습니다.
평가
우리는 이 프로젝트를 진행하면서 실제 환경에서의 Text-to-SQL 성능이 기존 벤치마크의 성능과 크게 다르다는 것을 깨달았습니다.
문제의 초점을 테이블 검색으로 맞추고, 데이터셋을 많은 양의 비정규화된 테이블로 구성하여 보다 현실적인 벤치마크를 생성하는 것이 훨씬 도움될 것 입니다.
Pinterest의 엔지니어링에 대한 자세한 정보는 엔지니어링 블로그 및 Pinterest Labs 사이트를 방문하여 확인 가능합니다. 또 현재 채용 중인 직무는 채용 페이지를 방문해 살펴보실 수 있습니다.