Project Nessie로 데이터 버전 관리하기
Apache Iceberg의 버전 관리를 돕는 Project Nessie를 살펴보았습니다.

Project Nessie
과거에는 분석 환경에서 데이터가 담긴 파일을 분산 처리하기 위해 주로 Apache Hive를 사용했다. 이때 Hive는 테이블 스키마 등의 메타데이터를 저장하고 API를 통해 저장된 메타데이터 정보를 전달하는 수단, 즉 카탈로그 서비스를 위해 Hive Metastore를 사용한다.
하지만 최근에 등장한 Apache Iceberg, Delta Lake와 같은 테이블 포맷들이 메타데이터를 Object Storage에 저장하게 되면서 Hive Metastore에 더는 크게 의존할 필요가 없어졌다. 대신 카탈로그의 목적이 테이블의 변경 이력이나 메타데이터의 저장 경로를 관리하는 방향으로 집중되었는데, 그 중 하나가 바로 Project Nessie이다.
Project Nessie는 Git으로부터 영감을 받아 만들어진 카탈로그 오픈 소스로서, Apache Iceberg를 사용할 때 엔지니어가 쉽게 데이터의 버전을 관리하고 필요하다면 이전 상태로 복원할 수 있도록 UI와 API를 제공하고 있다.
Base Concepts
Nessie의 기본 개념은 Git과 유사하다.
Commit
- 커밋은 특정 시점에서 테이블의 스냅샷을 가리키는 단위이다.
- 데이터의 변경 이력을 저장하여 이전 상태와의 차이를 관리한다.
Branch
- 브랜치는 데이터의 변경 이력을 독립적으로 관리할 수 있도록 만들어진 공간이다.
- Git처럼 “main” 브랜치를 기본으로 하고, 그 외 여러 브랜치를 생성하고 변경할 수 있다.
Tag
- 태그는 특정 커밋을 라벨링하여 중요한 시점을 표시한다.
Hash
- 해시는 각 커밋을 고유하게 식별하는 암호화된 문자열이다.
- Git처럼 특정 커밋을 참조하거나 되돌릴 때 사용된다.
Apache Iceberg
Hive를 운영하는데 있어서 엔지니어에게 가장 고통이 되는 지점은 Hive Metastore이다. 백엔드 데이터베이스로 MySQL 또는 Postgres와 같은 RDB를 사용하기 때문에, 데이터 사용자가 늘어남에 따라 부하 및 확장성 문제로 골치가 아파진다.
실제로 현업에서는 대량의 파티션을 업데이트하는 쿼리들로 인해 Hive Metadata의 성능 저하가 발생하고, 해당 쿼리가 쿼리 엔진의 컴퓨팅 리소스를 더 긴 시간 동안 점유함으로써 결국 쿼리 엔진의 성능 저하로 전파된다.
Apache Iceberg는 운영에 있어서 이러한 병목을 해소하기 위해 Object Storage에 메타데이터를 저장한다. 아래 이미지는 Iceberg를 다루는 블로그라면 한번 쯤 참조하고 있어서 따라 넣어 보았다.
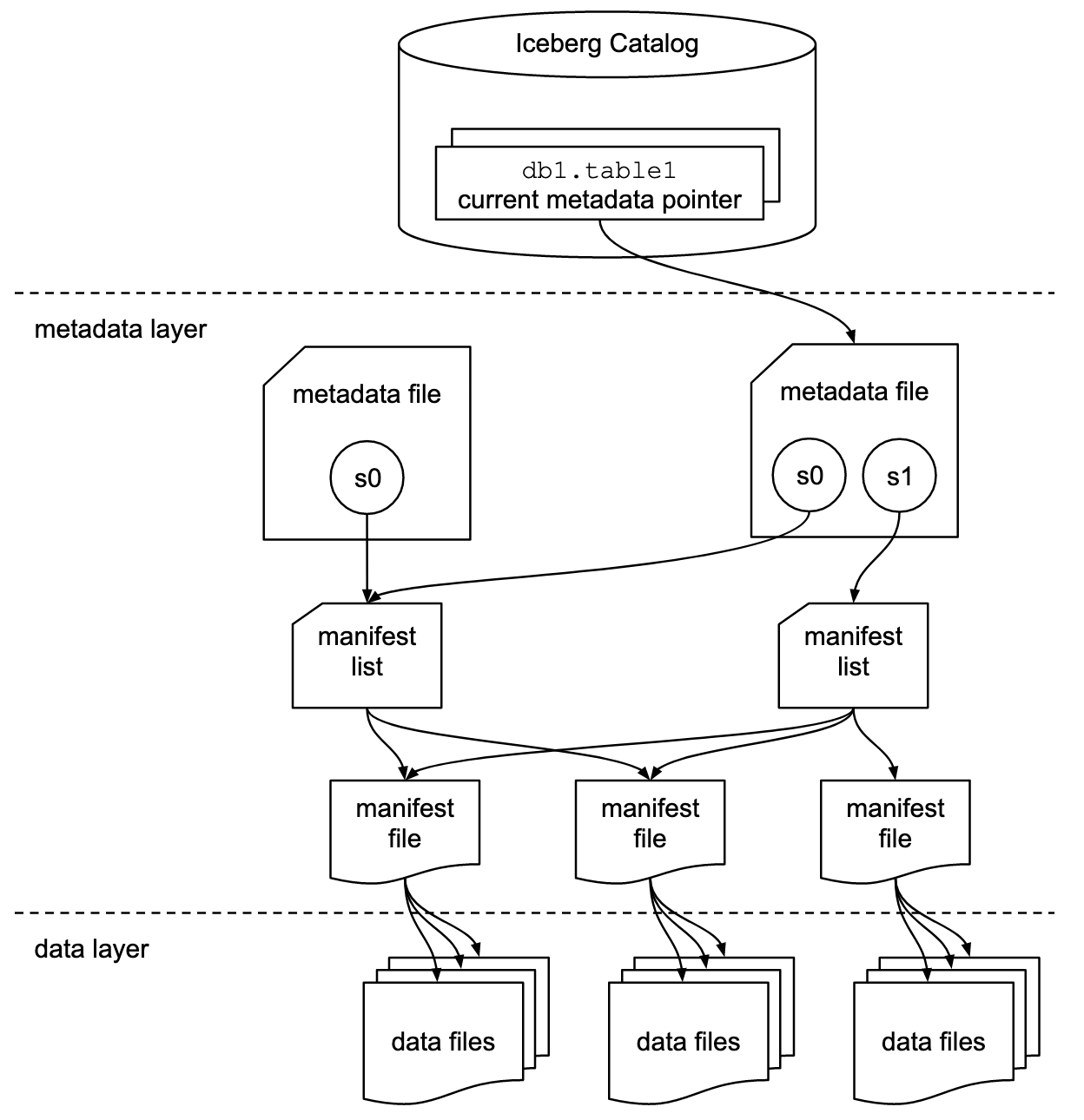 출처 - https://iceberg.apache.org/spec/#overview
출처 - https://iceberg.apache.org/spec/#overview
이외에도 Iceberg는 Hive의 여러 제한 사항을 해결하기 위한 많은 기능들을 지원하고 있다.
Hive vs Iceberg
| - | Hive | Iceberg |
|---|---|---|
| 유형 | Data Warehouse | Data Lake 용 테이블 포맷 |
| 목적 | 구조화된 데이터를 저장하고 처리하기 위한 플랫폼 | Data Lake에서 신뢰성 있고 효율적인 테이블 관리를 제공 |
| 데이터 저장소 | HDFS, S3, GCS 등과 같은 분산 파일 시스템 | 동일 |
| 지원 포맷 | Text, ORC, Parquet Avro | 동일 |
| 메타데이터 저장 | Hive Metastore(RDB) | HDFS, S3 등 Object storage |
| 카탈로그 | Hive Metastore | Hive Metastore 외 AWS Glue, Nessie 등 |
| 데이터 업데이트 | 데이터 수정, 삭제 시 파일 전체를 다시 작성해야 함 | 데이터 수정, 삭제 및 병합 작업 지원 |
| 분산 환경 | Hive Metastore와 MapReduce 중심 | Spark, Flink, Presto와 같은 분산 처리 엔진과 호환 가능 |
| 타임 트래블 | 지원 안 함 | 지원 (과거 스냅샷 조회 가능) |
| 병렬 작업 | 제한적 (충돌 방지 기능이 부족함) | 멀티 브랜칭 및 병합 작업 지원 (Nessie와의 연동으로 더욱 강력해짐) |
| 분석 작업 | 전통적인 배치 처리에 적합 | 실시간 및 배치 처리 모두에 적합 |
Practice
이제 Docker를 이용해 Iceberg와 Nessie를 테스트하는 환경을 띄워보려고 한다. Iceberg 테이블 포맷으로 테이블을 만든 후, Nessie로 버전 관리가 가능한지 확인해보자.
다음 Github 링크에 상세한 내용을 정리해 두었습니다.
Docker Configs
우선 Object Storage로는 MinIO를 세팅한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
minio:
container_name: minio
image: minio/minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_DOMAIN: minio
volumes:
- ./docker/volume/minio:/data
command: ["server", "/data", "--console-address", ":9001"]
healthcheck:
test: ["CMD", "mc", "ready", "local"]
interval: 10s
retries: 3
start_period: 5s
restart: unless-stopped
minio-client:
container_name: minio-client
image: minio/mc
entrypoint: >
/bin/bash -c "
mc config --quiet host add storage http://minio:9000 minio minio123 || true;
mc mb --quiet --ignore-existing storage/iceberg || true;
"
environment:
AWS_ACCESS_KEY_ID: minio
AWS_SECRET_ACCESS_KEY: minio123
AWS_REGION: ap-northeast-2
AWS_DEFAULT_REGION: ap-northeast-2
S3_ENDPOINT: http://minio:9000
S3_PATH_STYLE_ACCESS: true
depends_on:
minio:
condition: service_healthy
restart: "no"
다음은 카탈로그 역할을 할 Nessie이다. 백엔드로 Postgres, MongoDB 등을 사용할 수 있지만 로컬 개발을 위한 In-memory 기능도 지원하고 있다.
1
2
3
4
5
6
7
8
9
nessie:
container_name: nessie
image: ghcr.io/projectnessie/nessie:0.101.3
ports:
- "19120:19120"
- "9091:9000"
environment:
- nessie.version.store.type=IN_MEMORY
restart: unless-stopped
마지막으로 SQL 쿼리 엔진은 Trino 혹은 Dremio를 선택한다. Trino의 경우 /etc/trino/catalog 경로에서 Iceberg connector와 Catalog type을 구성할 수 있다.
앞서 설명했다시피 Iceberg는 메타데이터 저장을 위해 Object storage를 사용하므로, MinIO 연결 정보를 함께 작성해주자.
[iceberg.properties]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
connector.name=iceberg
iceberg.catalog.type=nessie
# Trino supports Nessie API V2 as of 450
iceberg.nessie-catalog.uri=http://nessie:19120/api/v2
iceberg.nessie-catalog.ref=main
iceberg.nessie-catalog.default-warehouse-dir=s3://iceberg
fs.native-s3.enabled=true
s3.endpoint=http://minio:9000
s3.region=ap-northeast-2
s3.aws-access-key=minio
s3.aws-secret-key=minio123
s3.path-style-access=true
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
trino:
container_name: trino
hostname: trino
image: trinodb/trino:450
ports:
- "543:543"
volumes:
- ./docker/trino/etc:/etc/trino
- ./docker/volume/trino:/var/lib/trino/data
depends_on:
hive-metastore:
condition: service_healthy
nessie:
condition: service_started
restart: unless-stopped
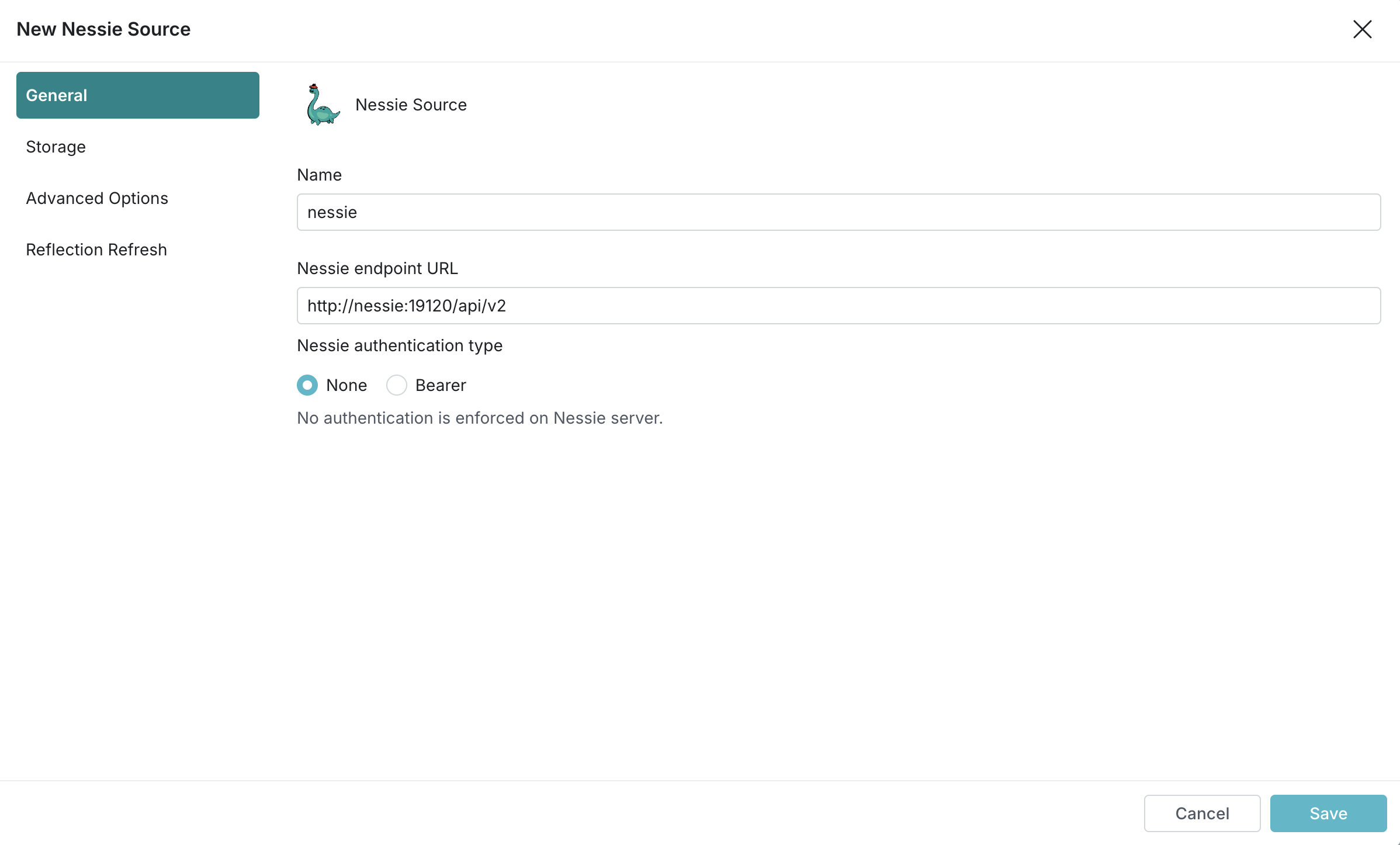
만약 Apache Dremio를 사용한다면, Trino와 달리 Web에서 Nessie를 등록해야 한다. 참고로 debug.addDefaultUser=true 설정을 키면 Web에 접근할 때 Default credential을 사용할 수 있다.
- Username:
dremio - Password:
dremio123
1
2
3
4
5
6
7
8
9
10
11
dremio:
container_name: dremio
image: dremio/dremio-oss:latest
ports:
- "9047:9047"
- "31010:31010"
- "32010:32010"
environment:
- DREMIO_JAVA_SERVER_EXTRA_OPTS=-Dpaths.dist=file:///opt/dremio/data/dis -Ddebug.addDefaultUser=true
volumes:
- ./docker/volume/dremio:/op/dremio/data
Apache Dremio
이번 글에서는 Dremio 공식 가이드를 참고하여, Dremio 쿼리 엔진에서 Nessie를 테스트해보았다.
먼저 Docker compose로 위의 모든 컴포넌트를 실행시킨 후, 9047 포트를 통해 Dremio UI에 접근하자.
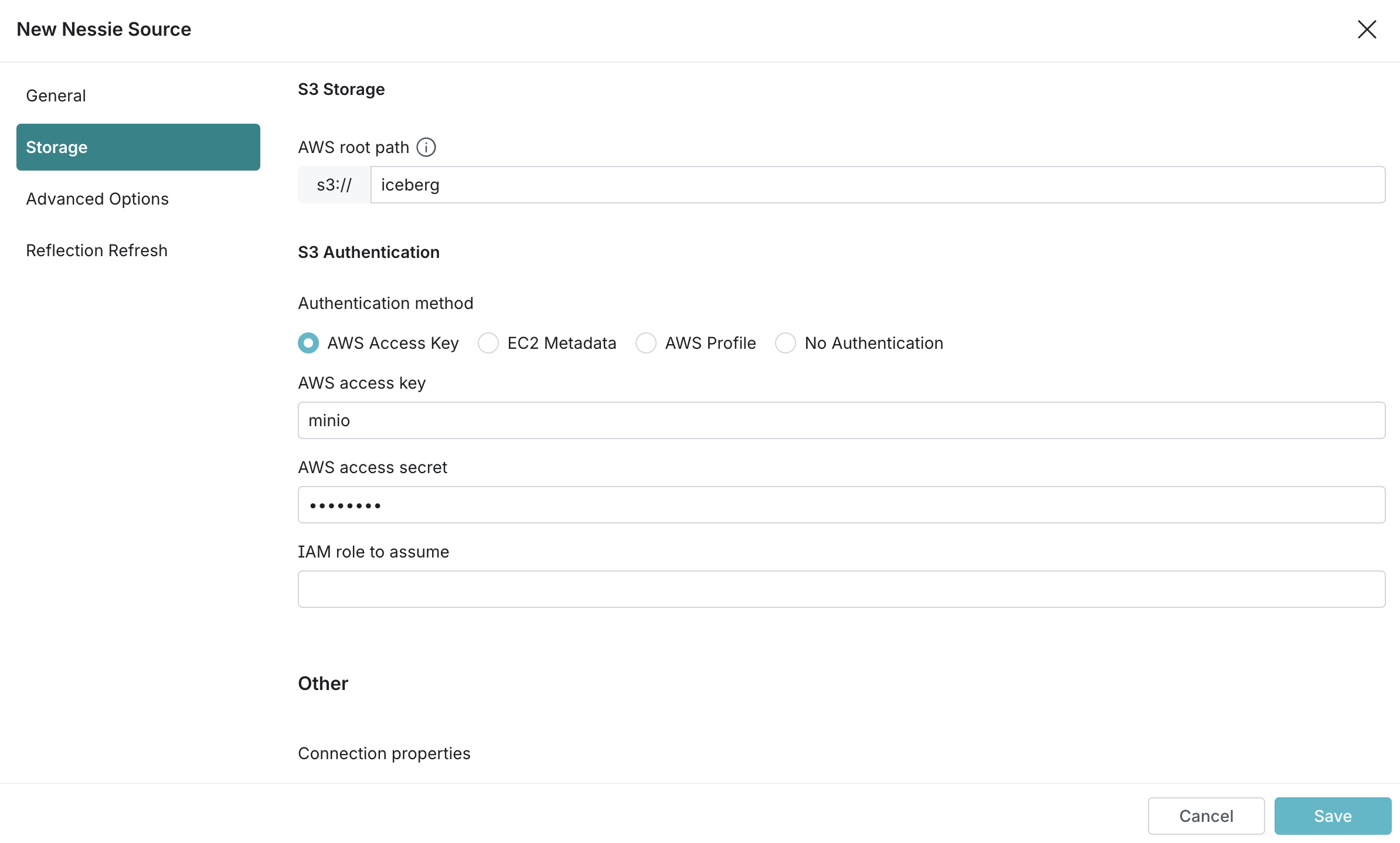
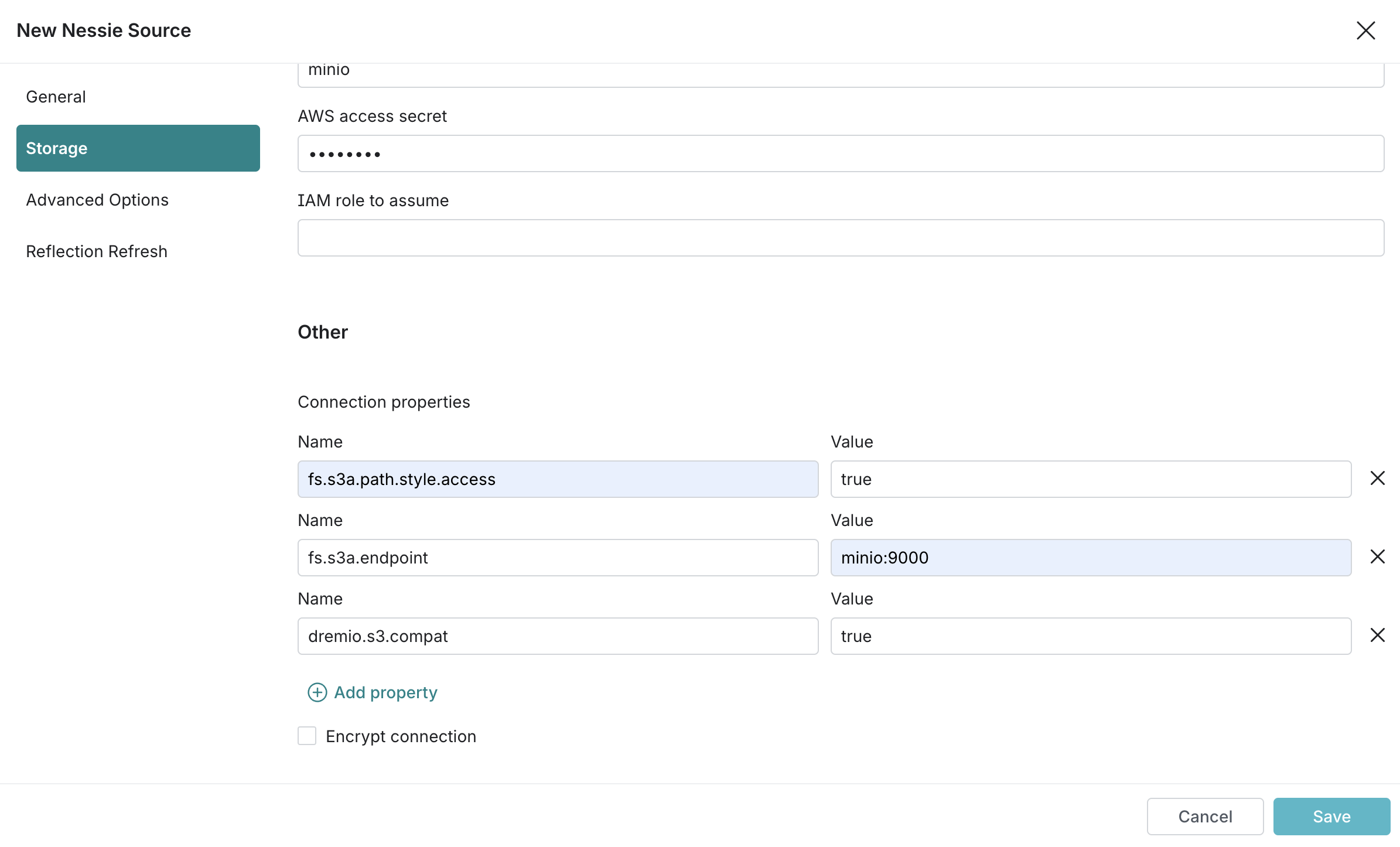
Web에 접속하여 Source에 Nessie API URL과 S3 Path를 등록해준다. 이때 Connection properties에 다음 key-value 값을 채워준다.
fs.s3a.path.style.access:truefs.s3a.endpoint:minio:9000dremio.s3.compat:true
Nessie Catalog
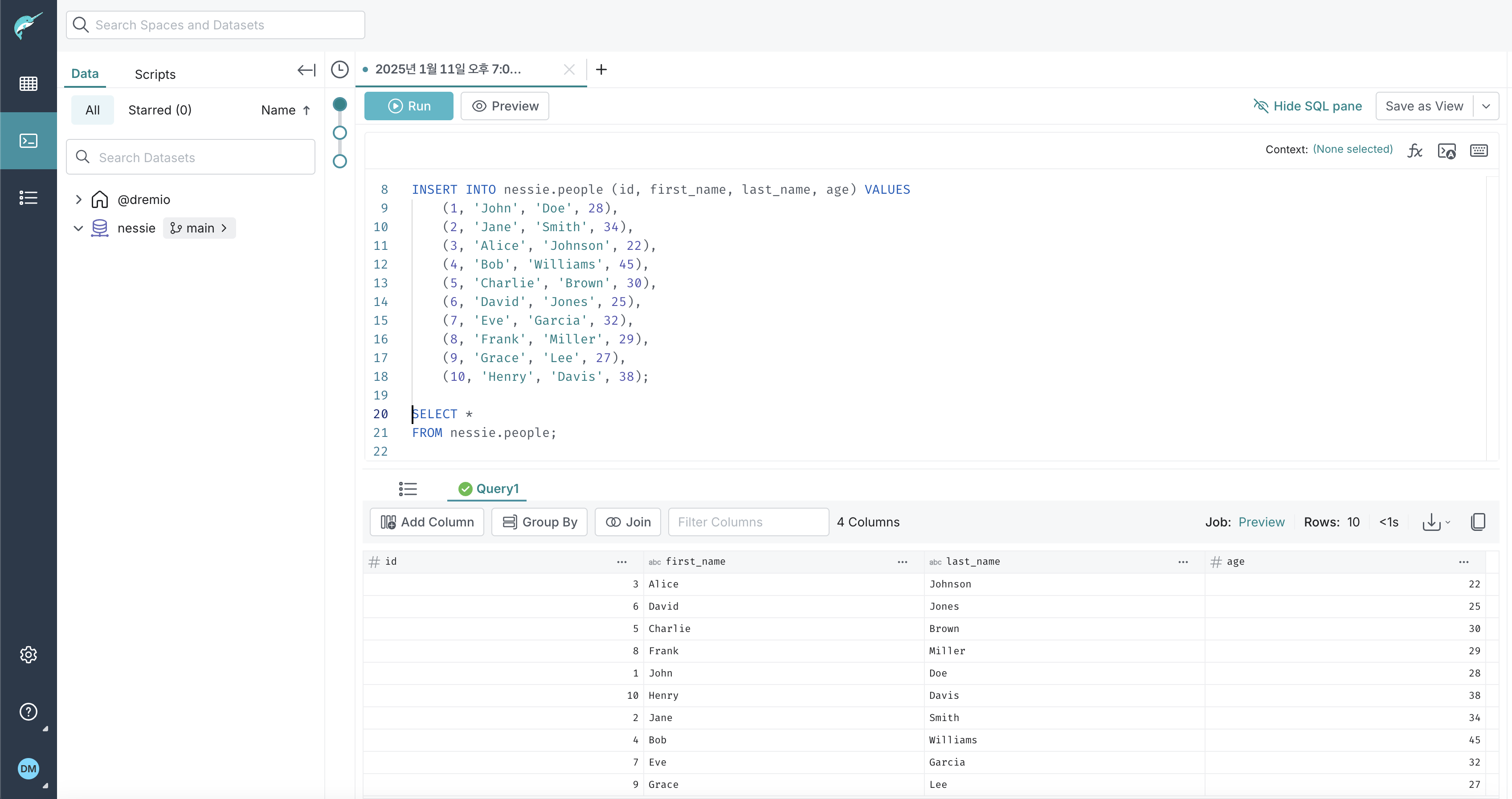
이제 nessie 카탈로그 아래에 people 테이블을 생성하고 데이터를 넣어보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
CREATE TABLE nessie.people (
id INT,
first_name VARCHAR,
last_name VARCHAR,
age INT
) PARTITION BY (truncate(1, last_name));
INSERT INTO nessie.people (id, first_name, last_name, age)
VALUES
(1, 'John', 'Doe', 28),
(2, 'Jane', 'Smith', 34),
(3, 'Alice', 'Johnson', 22),
(4, 'Bob', 'Williams', 45),
(5, 'Charlie', 'Brown', 30),
(6, 'David', 'Jones', 25),
(7, 'Eve', 'Garcia', 32),
(8, 'Frank', 'Miller', 29),
(9, 'Grace', 'Lee', 27),
(10, 'Henry', 'Davis', 38);
SELECT *
FROM nessie.people;
[실행 결과]
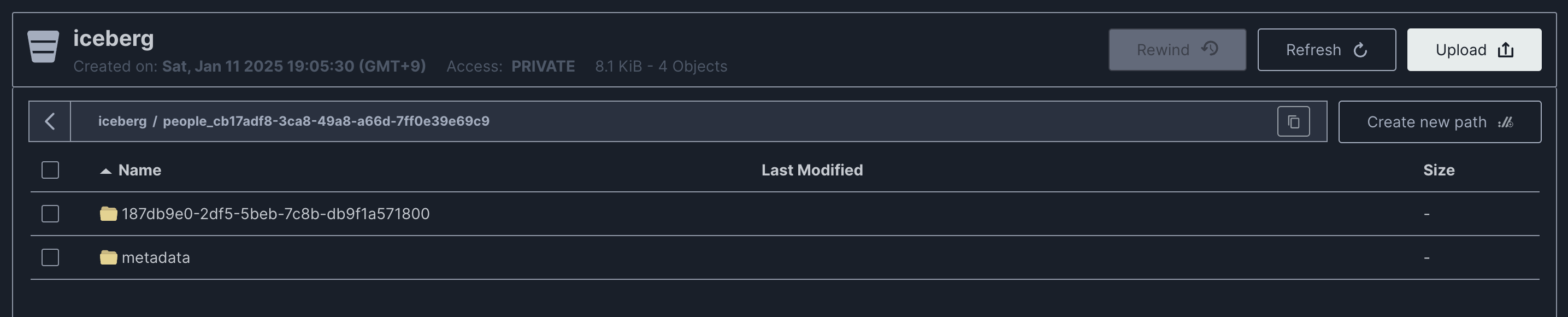
9001 포트로 MinIO에 접속해 데이터와 메타데이터가 생성되었음을 확인할 수 있다.
Branch
다음으로 브랜치를 생성해보자. 하기의 SQL로 ingest 브랜치를 생성하고 같은 테이블에 새로운 데이터를 추가하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE BRANCH ingest AT BRANCH main IN nessie;
INSERT INTO nessie.people AT BRANCH ingest (id, first_name, last_name, age)
VALUES
(21, 'Samuel', 'Graham', 42),
(22, 'Tina', 'Gray', 37),
(23, 'Ursula', 'Green', 45),
(24, 'Victor', 'Gibson', 29),
(25, 'Wendy', 'Gates', 31),
(26, 'Xavier', 'Graves', 28),
(27, 'Yasmine', 'Gomez', 30),
(28, 'Zane', 'Goodman', 33),
(29, 'Aria', 'Guthrie', 25),
(30, 'Brock', 'Garner', 40);
SELECT COUNT(1) FROM nessie.people AT BRANCH ingest;
[실행 결과]
1
20
그런데 main 브랜치로 다시 돌아와서 테이블을 조회해보면 ingest 브랜치에서 추가한 데이터는 반영되지 않았음을 볼 수 있다.
1
SELECT COUNT(1) FROM nessie.people AT BRANCH main;
[실행 결과]
1
10
ingest 브랜치를 main 브랜치에 병합하면 데이터 추가가 main 브랜치에도 반영된다.
1
2
MERGE BRANCH ingest INTO main IN nessie;
SELECT COUNT(1) FROM nessie.people AT BRANCH main;;
[실행 결과]
1
20
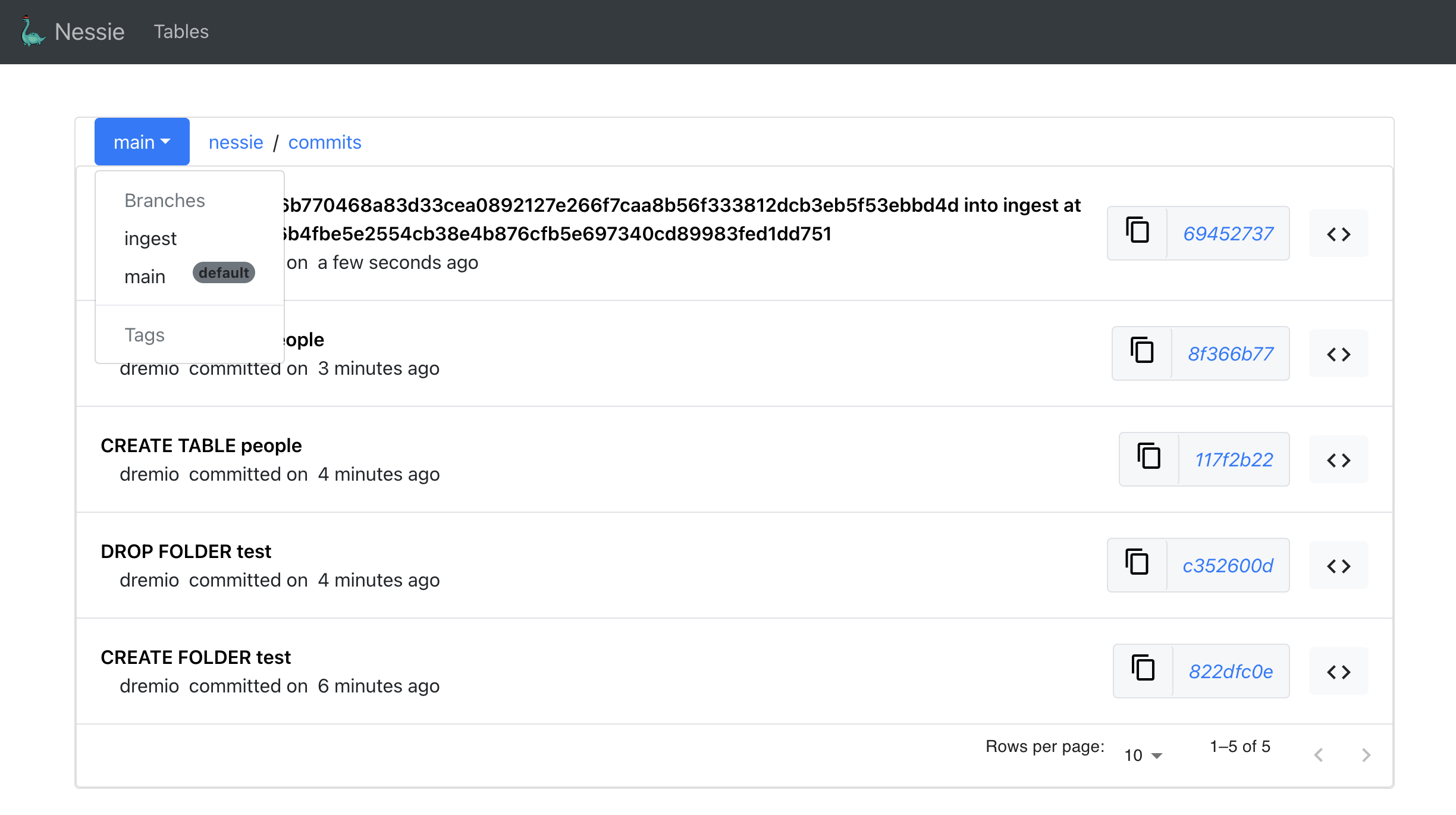
Commit History
마지막으로 1912 포트에 접근하여 Nessie UI에서 지금까지 생성한 브랜치 및 실행했던 커밋들을 확인할 수 있다.
고찰
이번 글을 통해 Iceberg와 함께 사용 가능한 카탈로그인 Nessie를 공부해보았다. 개인적으로 이런 데이터 버전 관리 도구를 사용한다면 다음과 같은 장점들이 있다고 생각한다.
1. 환경 분리
브랜치와 태그를 활용하면 데이터의 복사 없이도 분석 환경을 Staging 환경과 Prod 환경으로 분리할 수 있다. 그리고 Staging 환경에서 계산된 데이터를 Prod 환경에 적용하기 전에, Greate Expectation(GX) 이나 Soda 같은 데이터 품질 검사(DQ Validation) 단계를 추가하여 통과하지 못하면 Prod에 반영하지 않는 워크플로우를 만드는 것이다.
결과적으로 데이터 신뢰도를 강화할 수 있는 한 가지 수단이 될 수 있다.
2. 데이터 복원
데이터 파이프라인에 수정이 발생하는 경우 데이터에 의도하지 않은 누락, 오염 등이 발생할 수 있다. 기존에는 로직을 다시 롤백하고 데이터 파이프라인을 재실행함으로써 제법 긴 시간이 걸렸다면, 이제는 이전 커밋으로 데이터를 롤백하는 것만으로도 빠르게 복구가 가능하다.
또 데이터가 덮어 써진 경우에도 이전 스냅샷을 참조하여 특정 분석 결과를 재현할 수 있다.
3. 협업 효율 향상
거의 그럴 일 없겠지만 데이터 마트와 같이 복잡한 로직을 두 명 이상의 엔지니어가 수정해야 할 때가 있다. 이때 상호간의 간섭을 최소화하고 독립적으로 테스트할 수 있도록 브랜치를 나누어 작업이 가능하다.