Multiple GPU로 분산 학습 시키기
Multiple GPU로 분산 학습 시키기
모델 학습의 어려움
1. 문제점
- 하나의 GPU로는 학습이 너무 느림
- 하나의 GPU 메모리만으로 모델의 가중치를 감당하기 어려움
해결책
- 배치 사이즈 줄이기
- 학습 속도가 배치 사이즈에 비례하여 감소
- 과접합으로 인한 정확도 저하
- 모델 사이즈 줄이기
- 낮은 정확도
- 모델 사이즈가 클 수 밖에 없는 경우 존재
- Memory-offloading
- 학습 시 메모리 효율 좋음
- 학습 속도 저하
- 분산 학습 with Multi-GPU
- 개발 난이도가 높음
- 비싼 학습 비용
분산 학습의 3가지 요소
1. Task Distribution
[Data Parallelism]
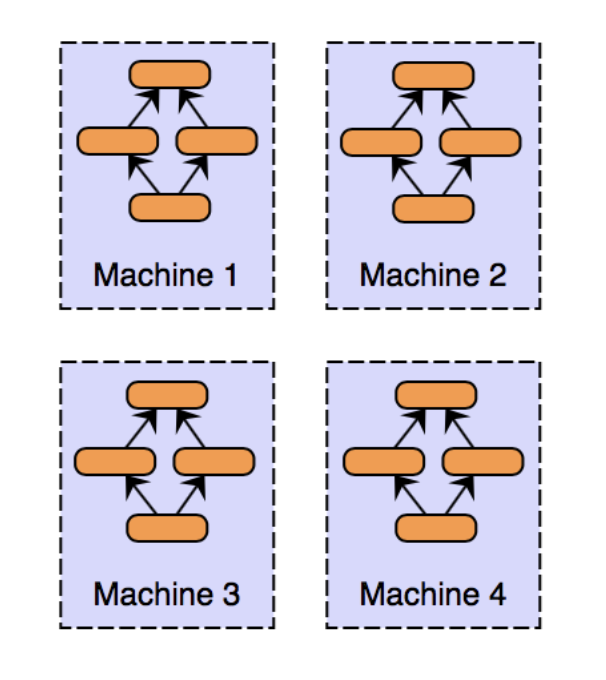 출처 - Intro Distributed Deep Learning
출처 - Intro Distributed Deep Learning
- 데이터를 각 GPU 장치로 분산
- parameter device에서 gradient 통합
[Model Parallelism]
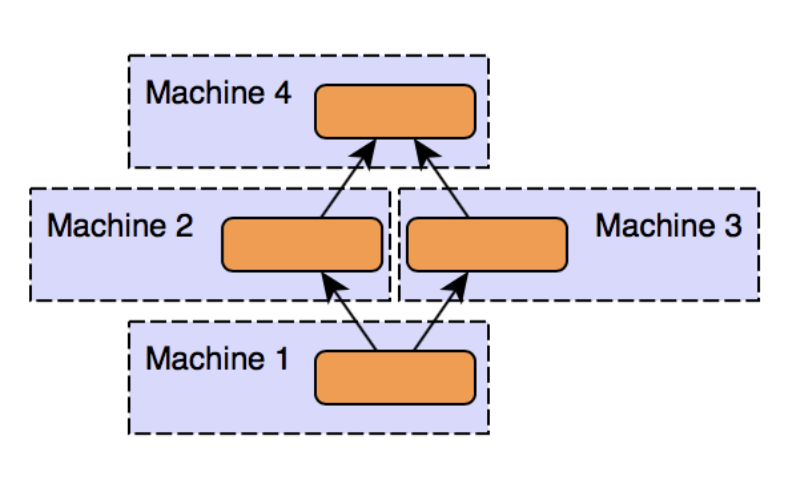 출처 - Intro Distributed Deep Learning
출처 - Intro Distributed Deep Learning
- 모델(tensor or layer)을 각 GPU 장치로 분산
- 모델을 하나의 GPU 장치에 할당하기 어려운 경우 사용
2. Parameter Synchronous
[Synchronous Update]
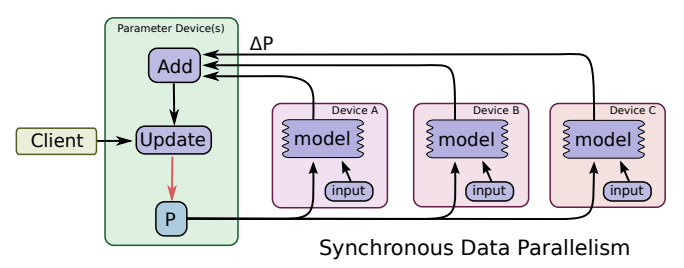 출처 - TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
출처 - TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
- 각 GPU 장치로 분산된 모델을 동기적으로 업데이트
- 지연이 있지만 수렴이 빠름
- 장치의 개수가 많으면 불리
[Asynchronous Update]
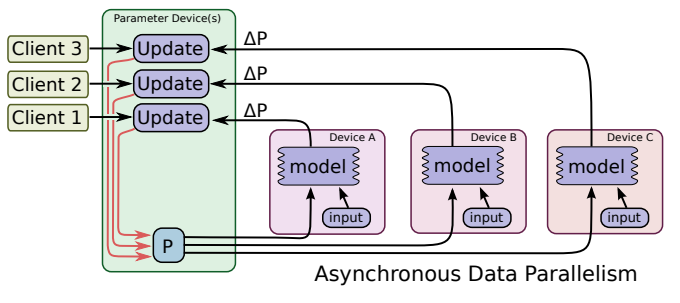 출처 - TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
출처 - TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
- 각 GPU 장치로 분산된 모델을 비동기적으로 업데이트
- 지연은 없지만 수렴이 느림
- 장치의 개수가 많을 때 사용
3. Gradient Aggregation
[All-Reduce]
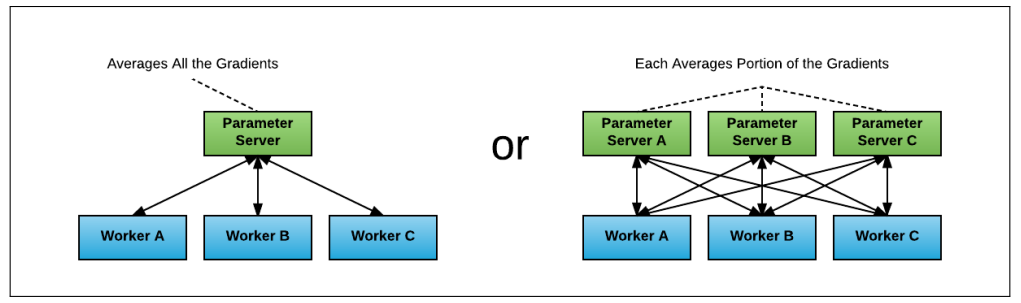 출처 - Horovod: fast and easy distributed deep learning in TensorFlow
출처 - Horovod: fast and easy distributed deep learning in TensorFlow
- 각 GPU 장치에서 계산한 gradient를 하나 또는 여러 parameter device로 모아서 집계
- Parameter device에 메모리 및 네트워크 부하 집중
[Ring All-Reduce]
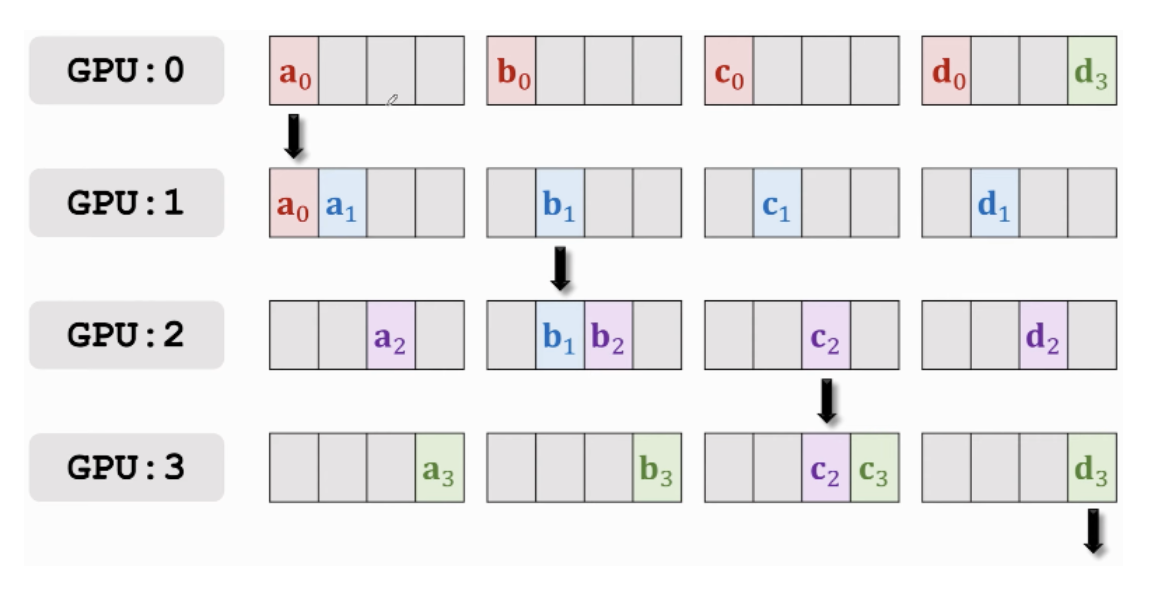
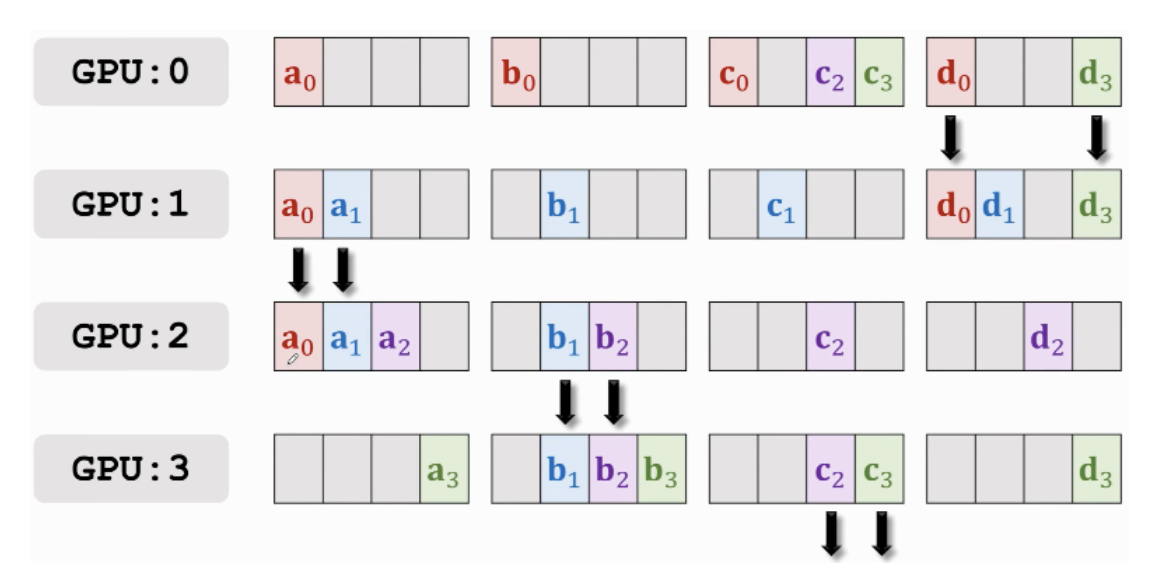
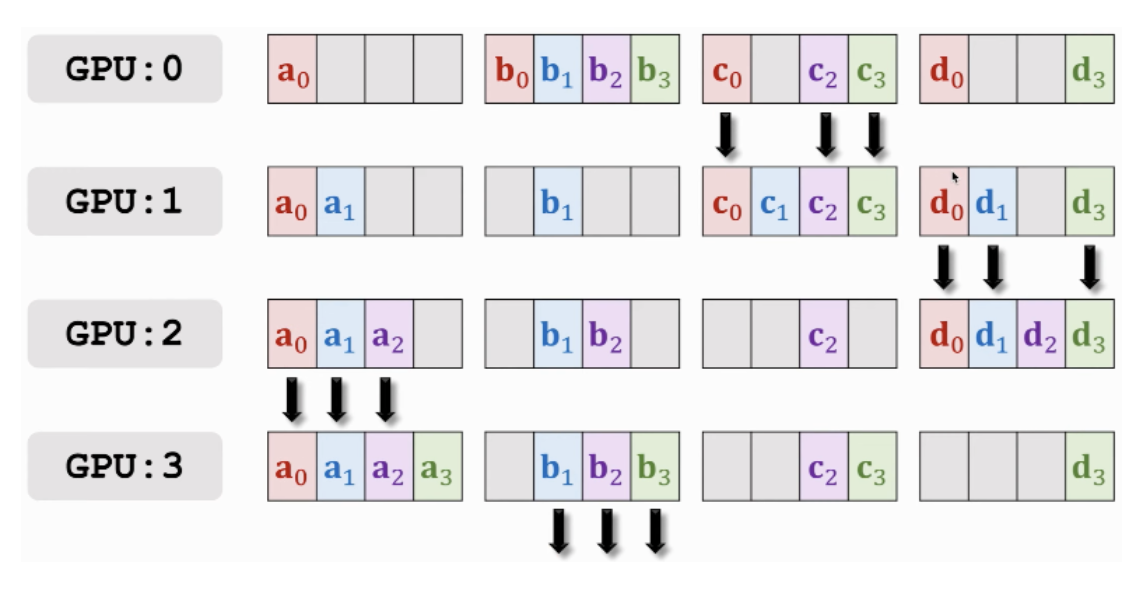 출처 - Parallel Computing for Machine Learning
출처 - Parallel Computing for Machine Learning
- 각 GPU 장치를 순환하며 gradient 일부를 전송하는식으로 gradient를 취합 및 공유
Task Distributions
1. Data Parallelism
- DP (Data Parallelism)
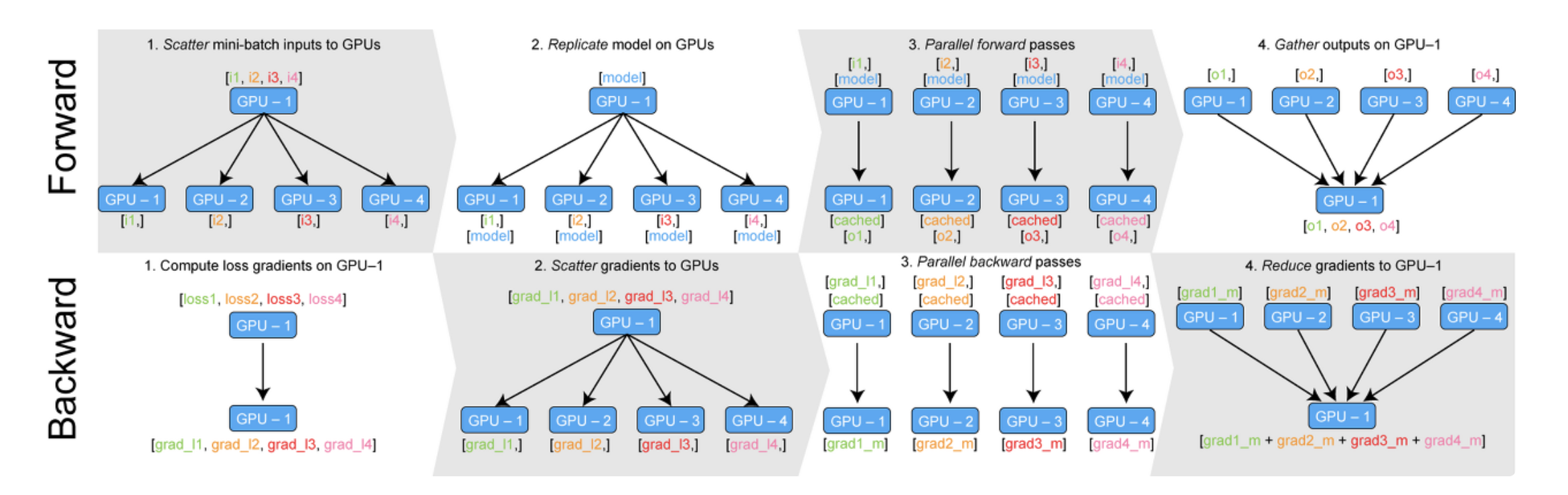 출처 - Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
출처 - Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- input batch → scatter → forward → logit (=output of model) → gather → loss (=error with label) → scatter → backward → gradient → gather → update models
- Single Node / Single Process / Multi Thread
- 가장 쉽고 개발이 빠른 방법
- 하나의 장치에 데이터를 모으기 때문에, 리소스를 충분히 사용하지 못하고 하나의 장치에서 오버헤드 발생
- DDP (Distributed Data Parallelism)
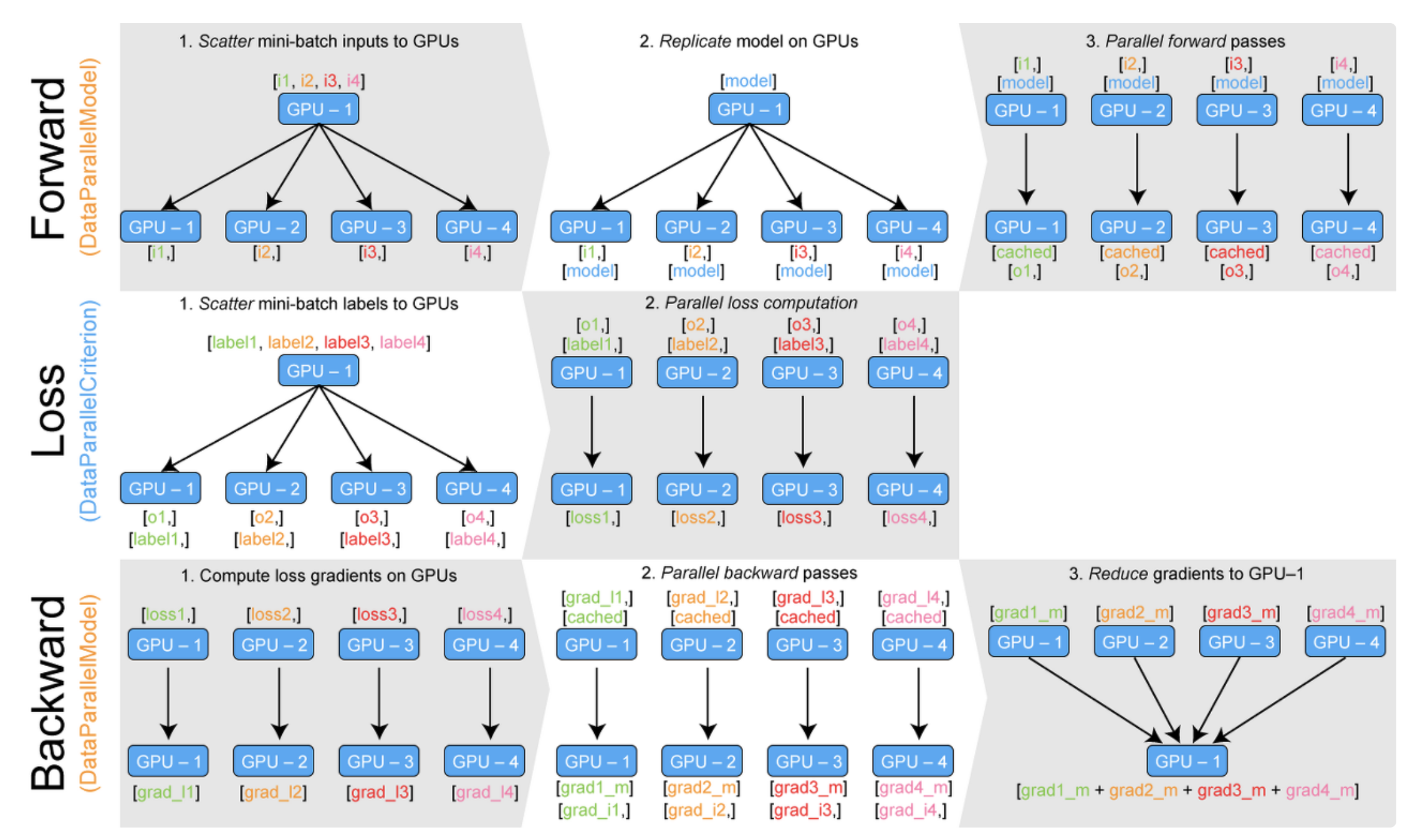 출처 - Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
출처 - Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- input batch & label → scatter → forward → logit → loss → backward → gradient → gather → update models
- Multi Node or Single Node / Multi Process
- main process 아래에 multi process를 생성하여 각 process 마다 하나의 GPU와 통신하여 학습을 진행
2. Model Parallelism
Tensor Parallelism (TP)
- 모델의 가중치(= tensor)를 여러 chunk로 나누어(= shard) 지정된 GPU에 할당
- 각 shard는 학습 단계에서 서로 다른 GPU에서 병렬로 처리되며, 단계가 끝나면 결과를 동기화
- Horizontal Parallelism이라고도함
Pipeline Parallelism (PP)
- 모델의 layer를 여러 GPU에 분산
- 따라서 한 GPU가 한개의 layer를 가질 수도 있고, 여러 layer를 가질 수도 있음
- 각 GPU들은 병렬로 처리를 하되, 서로 다른 학습 단계일 수 있음
- 다른 GPU가 계산하는 동안 다음 학습 단계를 미리 연산
Zero Redundancy Optimizer (ZeRO)
- TP와 유사하게, 가중치를 sharding하지만, gradient 계산이 끝날때 전체 가중치를 동기화하지 않음
- 다양한 방법으로 CPU offloading을 지원하며, 제한된 gpu memory 환경을 보충
- memory fragmentation을 줄이기 위해 tensor의 lifecycle를 관리하기도 함
- ZeRO-1
- Optimizer State Partitioning
- ZeRO-2
- { ZeRO-1 } + { Gradient Partitioning }
- ZeRO-3 1. { ZeRO-2 } + { Model Parameter Partitioning }
3. Hybrid Parallelism
Sharded DDP
- All-Reduce = Reduce-Scatter + All-gather 관점으로 볼 수 있음
- input batch를 나누고 gradient를 집계하는 기존 DDP에서 추가로 weight와 optimizer state까지 sharding
- forward와 backward 계산 시에만 weight를 모아 연산
Scalability Strategy
- Single Node & Multi-GPU
- 모델이 하나의 GPP애 다 들어갈 수 있는 경우
- DDP - Distributed DP
- ZeRO - 상황에 따라 더 느릴 수 있음
- 모델이 하나의 GPP애 다 들어갈 수 없는 경우
- PP
- 인프라에 따라 다르지만 특수한 상황이 아니라면 PP가 ZeRO나 TP보다 빠름
- ZeRO
- TP
- PP
- 가장 큰 layer가 하나의 GPU에 들어갈 수 없는 경우
- ZeRO 쓸 수 없으면 무조건 TP
- ZeRO 쓸 수 있으면 DDP 까지
- 모델이 하나의 GPP애 다 들어갈 수 있는 경우
- Multi Node & Multi-GPU
- 노드 간 연결이 빠른 경우
- ZeRO
- 모델을 변경할 필요가 없음
- PP + TP + DP
- 통신을 덜 하지만 모델을 많이 변경해야함
- ZeRO
- 노드 간 연결이 느린 경우 + GPU 메모리가 적은 경우
- DP + PP + TP + ZeRO-1
- 노드 간 연결이 빠른 경우
This post is licensed under CC BY 4.0 by the author.