Vector Search - HNSW
Vector Search - HNSW
Hierarchical Navigable Small World
Approximate Nearest Neighbor (ANN) 알고리즘은 크게 세 가지 카테고리로 분류 가능
- Tree
- Hash
- Graph
HNSW는 이중 graph를 이용한 접근 방식에 속하며, 특히 Proximity Graph를 기반으로 함
- Proximity Graph란?
- vertex 간의 proximity를 기준으로 link를 결정하는 것
- 말 그대로 가까운 두 vertex를 연결하며, 이때 Euclidean Distance를 주로 이용함
- Hierarchical Navigable Small World는 Proximity Graph 보다 훨씬 복잡한 구조
다른 Vector Search 알고리즘과 달리 HNSW가 가진 특별한 장점은 증분 색인(incremental indexing)이 가능하다는 것
Fundamental Techniques
Probability Skip List
- Skip list는 sorted array를 빠르게 탐색하는 linked list 구조이며, 새로운 element를 추가하기 쉬움
- Link는 vertex 간의 연결을 의미하며, skip은 이러한 연결을 건너뜀을 의미
- Layer를 내려갈수록 link를 skip하는 횟수가 줄어듬
- ex) 11을 찾기 위해 다음과 같은 규칙으로 layer를 내려간다.
- 현재 vertex가 target(=11)보다 작으면 skip (오른쪽으로 이동)
- 현재 vertex가 target(=11)보다 크면 다음 layer (아래로 이동)
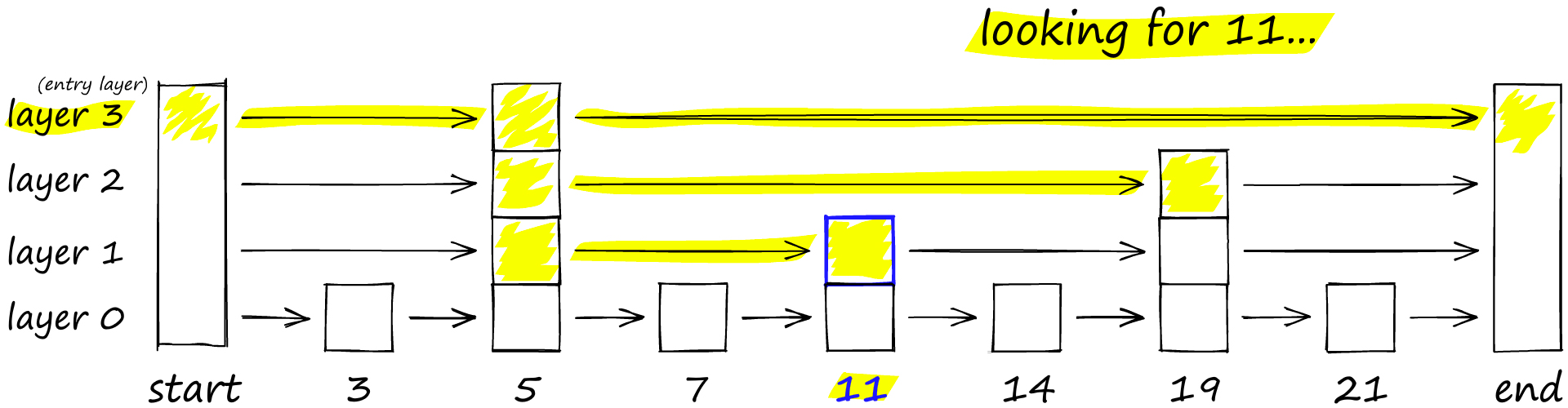
결국 HNSW는 빠른 검색을 위해 가장 높은 layer의 long edge를, 정확한 검색을 위해 낮은 layer의 short edge를 순회
Naviable Small World
- Navigable Small World는 long-range와 short-range link 구조를 가지도록 proximity graph를 만든다면, 탐색 시간을 poly / logarithmic 하게 줄일 수 있다는 아이디어
- Greedy Routing
- 미리 정해둔 entry point에서 출발
- Neighbor를 탐색하여 query vector와 가장 가까운 vertex로 이동
- 현재 vertex 보다 더 가까운 neighbor를 찾을 수 없을 때까지 진행
- 그러면 local minimum으로 수렴
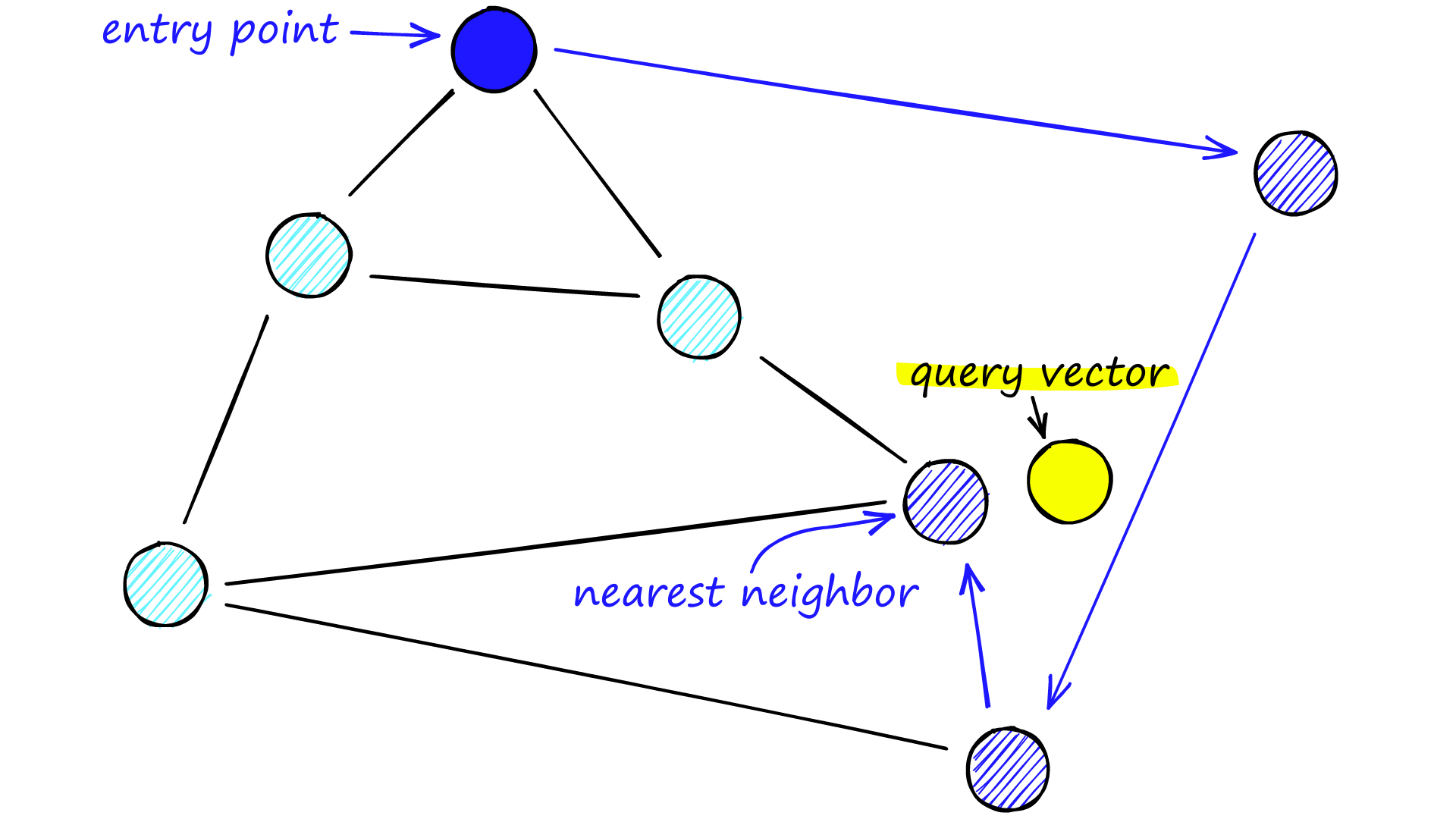
- Routing은 다음 두 가지 phase로 나뉨
- Zoom out
- lower degree vertex로 진입
- Zoom in
- higher degree vertex로 진입
- Zoom out
- Zoom out 구간에서는 neighbor 개수가 적어 탐색이 너무 일찍 끝나기 때문에 local minimum의 수렴이 그리 좋지 못함
- 탐색이 너무 일찍 멈출 확률을 줄이기 위해 vertex의 degree의 평균을 올리는 방법이 있음
- 그러면 network의 복잡도 및 탐색 시간이 증가
- 따라서 recall과 search speed 간의 trade off 존재
- 또는 higher dgree vertex 부터 탐색 (zoom in)
- 탐색 시간이 증가할 것이므로 vector dimension이 낮을 때 유리
- 탐색이 너무 일찍 멈출 확률을 줄이기 위해 vertex의 degree의 평균을 올리는 방법이 있음
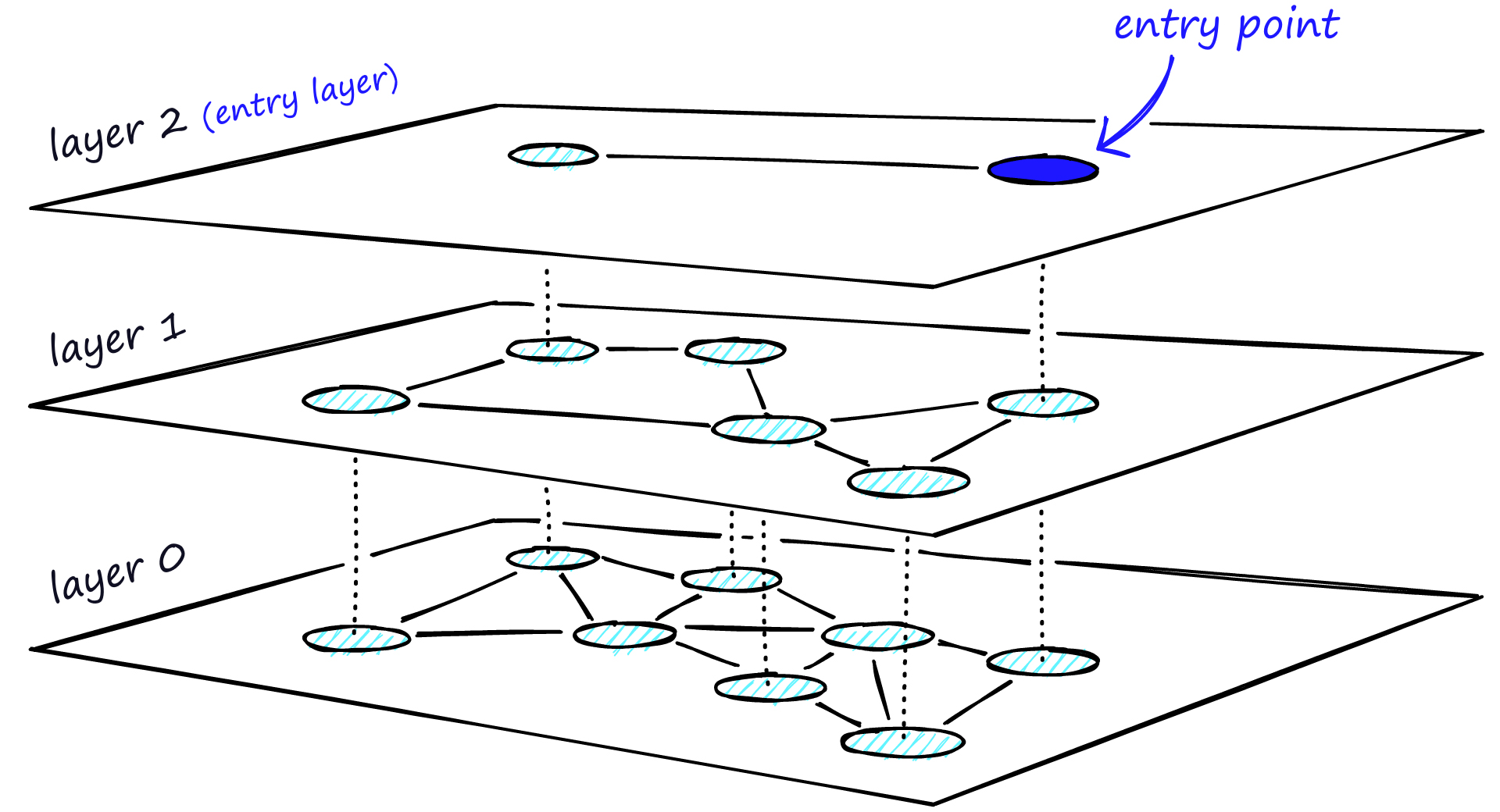
Structure
HNSW는 각 layer에 NSW를 적용한 계층 구조
- 가장 상위의 layer는 가장 긴 link를 가지며, higher degree vertex들임
- 아래로 내려갈수록 degree는 줄어들며, 따라서 zoom-in phase
- 위 layer에 존재하는 vertex는 아래 layer에도 존재
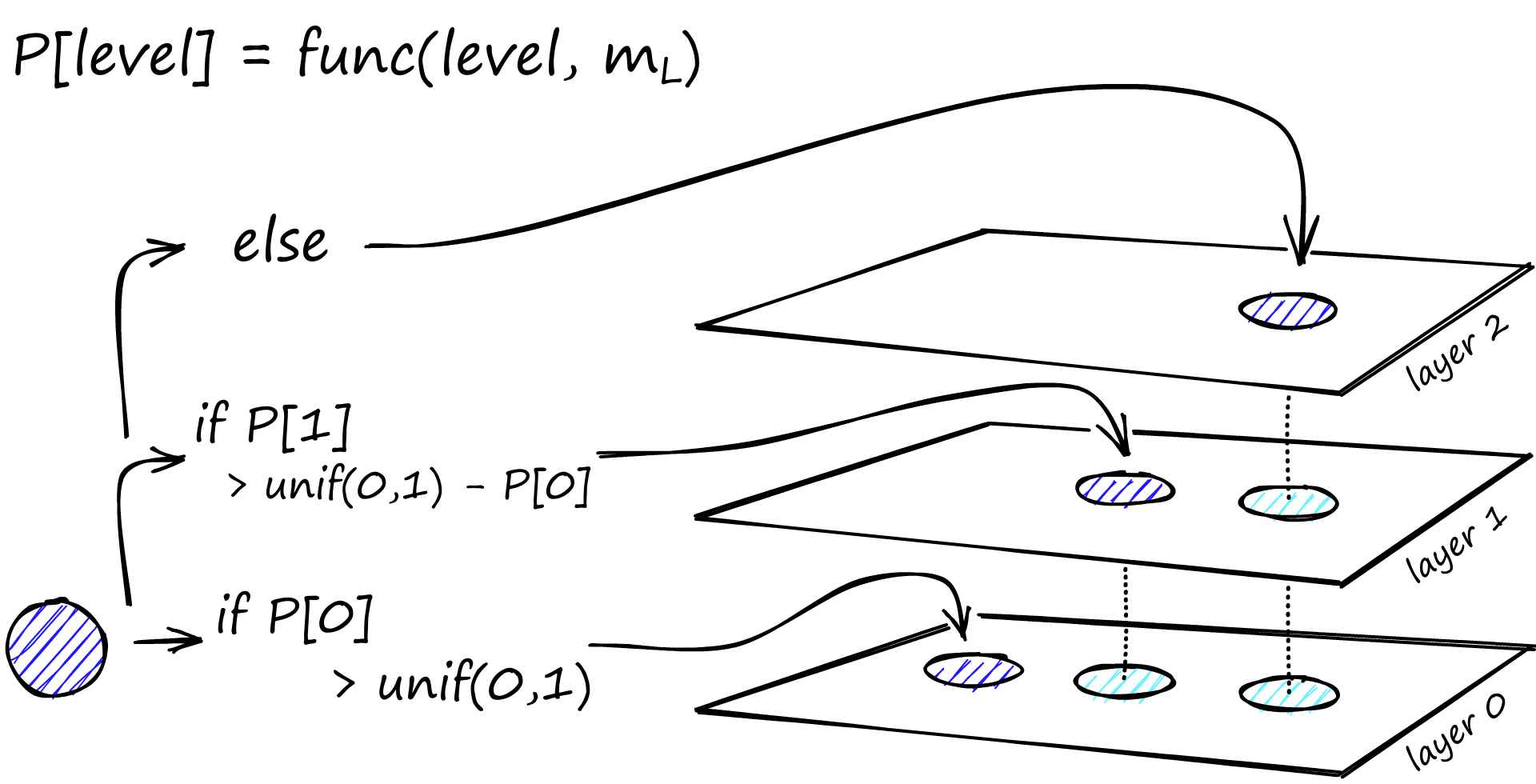
- 새로운 vertex는 확률적으로 layer에 추가됨
- 가장 아래부터 uniformly하게 포함
- 위로갈수록 cumulative하게 확률 계산
- Vertex가 존재하는 가장 상위의 layer를 insertion layer라 부름
Hyperparameter
- ef_search
- 한번에 탐색하는 nearest neighbor 개수
- ef_construction
- 그래프 생성 과정에서 탐색하는 nearest neighbor 개수
- M
- Vertex가 추가되었을 때, layer에서 가장 가까운 M개의 vertex를 골라 link를 붙임
- M_max
- Vertex 하나가 가질 수 있는 link의 최대 개수
- 가장 하위 layer는 최대 개수를 따로 설정 가능 (M_max0)
- layer간의 overlap을 최소화할 수록 성능에 좋다.
- level multiplier m_L을 낮추면 overlap이 최소화 where L := ( # of layer )
- 하지만 traversal time이 증가하므로 trade-off
- level multiplier의 가장 좋은 값은 1 / ln(M), M = ( # of neighbors ) (아래에서 자세히 설명)
- “A rule of thumb”
검색 과정
- 가장 상위 layer의 entry point로 진입
- 해당 layer에서 local minimum에 빠질때까지 greedy하게 nearest neighbor 탐색
- local minimum에 빠지면, 하위 layer로 진입
- 가장 하위 layer에서 local minimum에 빠질때까지 2 ~ 3 과정 반복
- ef_search 개의 nearest neighbor 선택
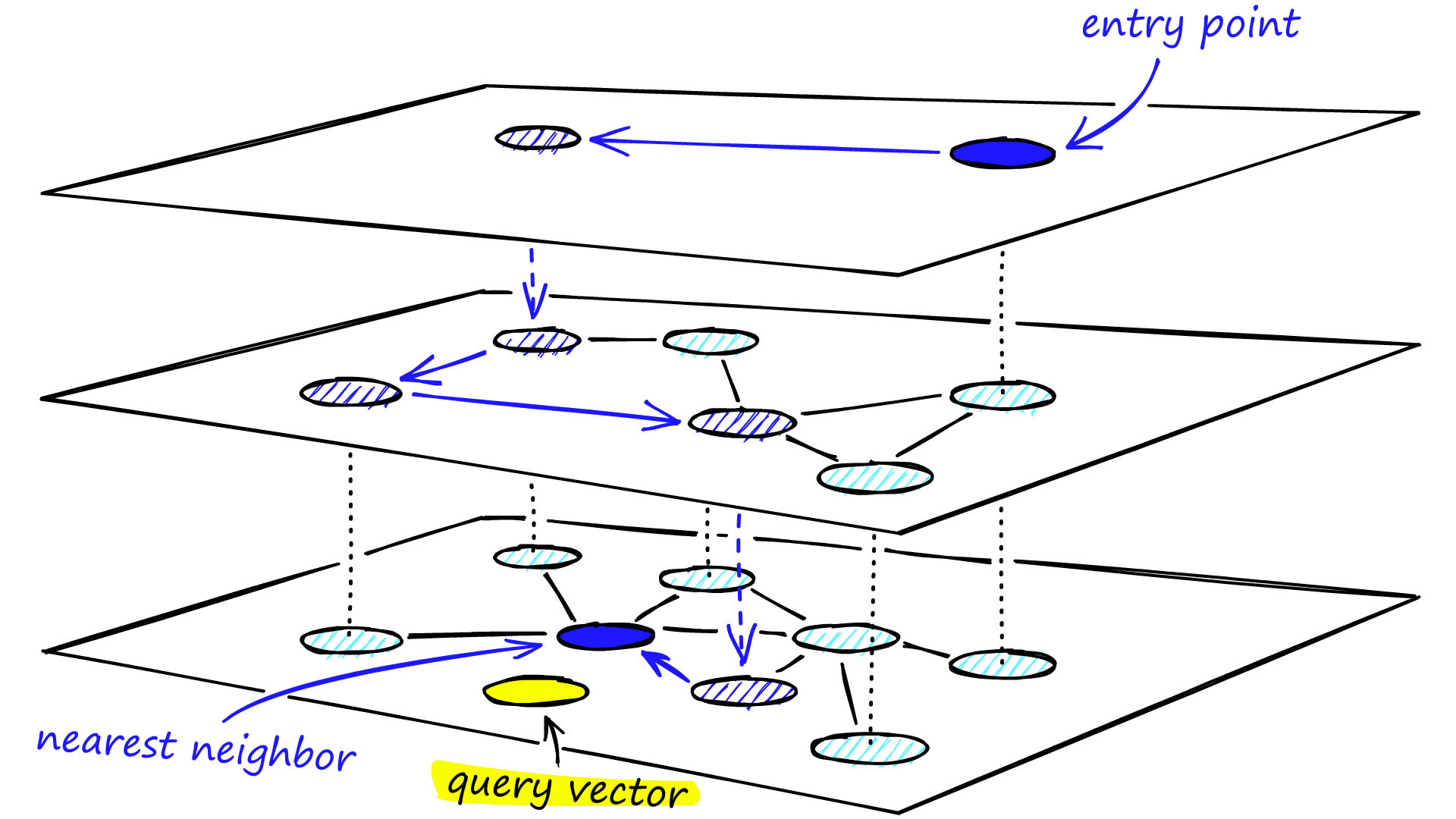
생성 과정
- 가장 상위 layer의 entry point로 진입
- Insertion layer에 도달할 때까지 가장 가까운 neighbor 선택 (ef_search = 1인 검색 과정)
- Insertion layer에 도달한 이후로는 nearest neighbor을 ef_construction 개 만큼 찾아 후보로 등록
- 후보 vertex 중 가장 가까운 M개를 선택하여 해당 layer에서의 link 추가
- 후보 vertex를 통해 하위 layer로 진입
Open source
Framework
Library
Reference
This post is licensed under CC BY 4.0 by the author.