DuckDB 파헤치기
DuckDB란?
DuckDB는 2019년 네덜란드의 두 데이터베이스 연구자, Mark Raasveldt와 Hannes Mühleisen로부터 탄생한 오픈소스이다.
여기서 duck은 오리를 의미한다. 하늘을 날고, 물에서 수영하며, 땅 위를 걸을 수 있는 오리처럼 다재다능하고 적응력이 뛰어난 시스템을 표방하였다. 공식 문서에 따르면 오리의 울음 소리가 데이터베이스 연구에 많은 영감을 줬다고 한다. ???
DuckDB는 데이터 과학자들이 데이터에만 집중할 수 있도록 다음과 같은 구조를 염두에 두고 만들어졌다.
Embedded Database
DuckDB의 창시자들은 데이터 과학자들이 데이터베이스를 구축하기 보다는, pandas나 dplyr과 같은 데이터프레임 라이브러리 사용을 선호할 것이라고 생각했다.
실제로 데이터베이스를 구축하고 운영하는데는 상당한 번거로움을 감수해야 하는데, 서버의 설치와 유지 비용, DB에 접근하기 위한 인증 등 연구 이외에 신경 써야할 것들이 많아지게 된다.
이러한 오버헤드를 줄이기 위해 창시자들은 SQLite의 접근 방식을 차용하여, 데이터 분석을 위한 Embedded(= In-Process) Database를 개발하고자 했다.
OLAP
모티브가 되었던 SQLite와 달리 DuckDB는 OLAP에 특화되어 있다. 복잡하고 오래 걸리는 집계, 크기가 큰 테이블 간의 조인 등을 높은 성능으로 수행하기 위해 DuckDB는 컬럼 기반(Columnar)의 벡터화(Vectorization) 기법을 채택하였다.
컬럼 기반의 데이터 처리는 필요로 하는 컬럼들만 읽기 때문에 디스크 IO 작업이 줄어들고, 중복된 값들이 캐시될 확률이 높아 CPU 메모리의 대역폭을 효율적으로 사용할 수 있다.
또한 implicit SIMD(Single Instruction, Multiple Data)를 지원하여 하드웨어 아키텍처에 구애받지 않고도 벡터화된 데이터를 병렬적으로 처리할 수 있다.
Relational DBMS
DuckDB는 SQL를 지원하는 relational DBMS이다. 따라서 이미 SQL에 친숙한 사람들은 어려움 없이 DuckDB를 조작할 수 있다. 뿐만 아니라 PostgeSQL을 기반으로한 현대적인 함수 및 데이터 타입을 지원하고 있어서 편의성이 높다.
예를 들어 QUALIFY 라는 예약어를 사용하여 window 함수가 적용된 필터를 걸 수 있으며, EXCLUDE 예약어를 사용하면 star expression(= *)에 예외를 적용할 수 있다.
또 List 타입을 사용할 때는 lambda expression으로 map-reduce를 구현할 수 있도록 build-in 함수들을 지원하고 있다.
마지막으로 tabular한 특성 덕분에 다른 dataframe 라이브러리들과의 연동이 매우 편리하다. 가령 Python에서는 다음과 같은 메서드를 호출해 Pandas Dataframe으로 변환시킬 수 있다.
1
2
3
import duckdb
pandas_df = duckdb.sql("SELECT 1").to_df()
Features
DuckDB는 다음과 같은 특징들을 갖고 있다.
1. Replacement Scan
만약 호출된 테이블이 카탈로그에 존재하지 않으면, DuckDB는 다른 데이터 소스를 찾아 대입한다. 예를 들어 Pandas의 데이터프레임이 할당된 변수명이나 파일의 경로를 테이블 이름 대신 사용할 수 있다.
1
2
3
4
5
import duckdb
import pandas as pd
tool_df = pd.DataFrame({"tools": ["pandas", "polars", "duckdb"]})
duckdb.sql("SELECT * FROM tool_df")
2. Parallelism
DuckDB는 “row group” 단위로 병렬 처리를 수행한다. 여기서 “row group”이란 parquet에서 데이터를 저장하는 방식에 사용되는 “row group”과 동일한 개념이다.
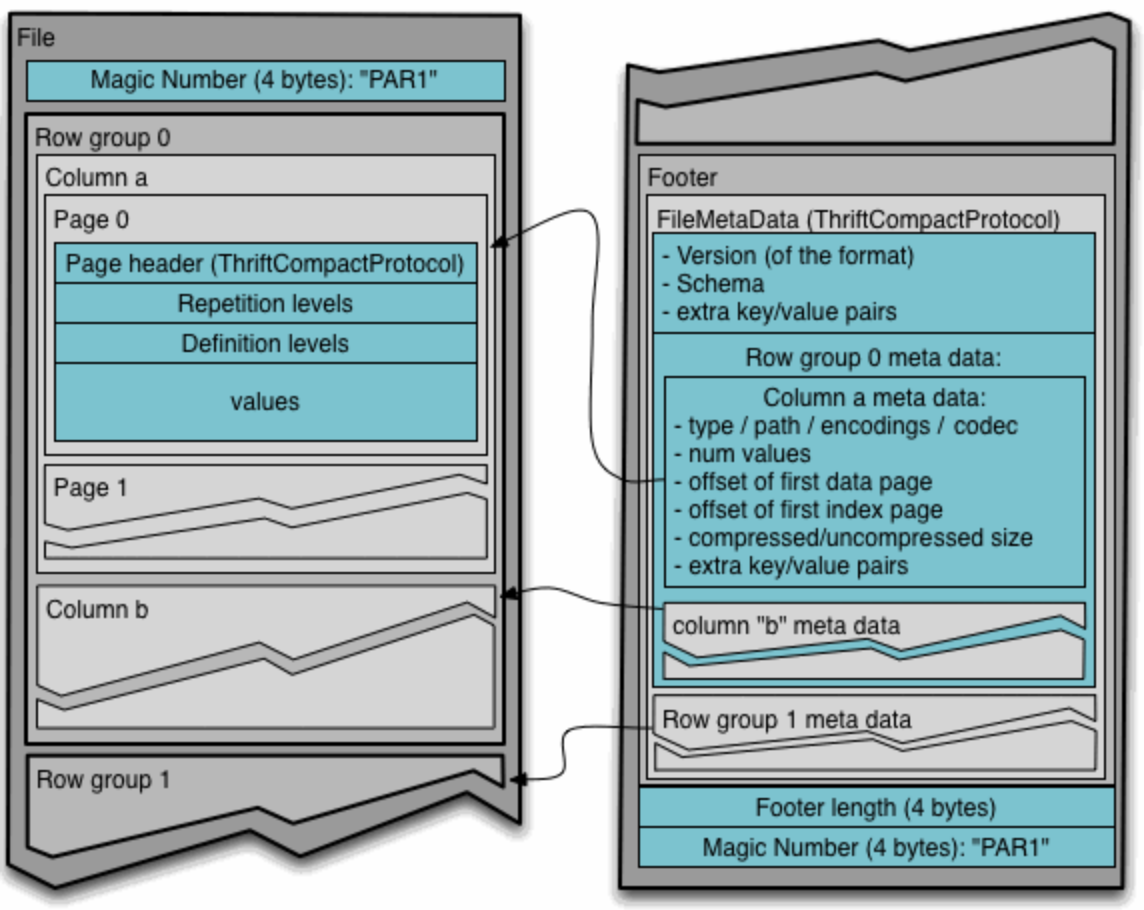
DuckDB의 데이터베이스에서 하나의 row group은 최대 $122,880$ 개의 row를 갖는다. 따라서 어떤 쿼리가 $k$ 개의 thread를 사용하고 있다면, 적어도 $k \times 122,880$개의 row를 읽고 있다는 의미이다.
3. Larger-than-memory Workload
Disk spill
어쩔 수 없이 모든 데이터를 스캔해야하는 Blocking Operation들이 분명 존재한다.
- Group by
- Order by
- Window functions
- Join
이런 operation이 포함된 쿼리가 실행될 때 더 이상 데이터를 in-memory로 처리할 수 없다면 성능을 포기해서라도 disk를 사용한다. 이때 DuckDB는 persistent 모드이거나
1
2
3
import duckdb
conn = duckdb.connect("/path/to/persistent_storage.db")
또는 in-memory 모드라면 offloading을 위한 임시 디렉토리 설정을 해주어야 한다.
1
SET temp_directory = '/path/to/temp_directory.tmp/';
그럼에도 불구하고 데이터의 크기가 너무 크거나 집계가 너무 복잡하다면 “out of memory” 예외가 발생할 수도 있다.
preserve_insertion_order
DuckDB는 데이터를 읽거나 쓸 때 데이터를 자동으로 정렬한다. 이는 정렬 시 parquet와 같은 columnar format들이 압축 및 인덱싱에 효과적이기 때문이다.
그러나 이러한 기능은 memory usage를 더 잡아먹게되므로, 만약 OOM이 발생한다면 해당 옵션을 비활성화하여 정렬을 하지 않는 방법도 존재한다.
1
SET preserve_insertion_order = false;
4. Compression
DuckDB는 데이터 저장 시 경량화를 위한 압축 알고리즘도 지원하고 있다. 압축을 수행할 때는 컬럼의 segment를 분석하고, 분석 결과를 토대로 효과적인 압축 알고리즘을 선택한다.
자세한 내용은 다음 링크를 참고하자.
4. Connection
DuckDB는 다른 데이터베이스들과 마찬가지로 connection을 만들어 재사용할 수 있다. 각 connection은 쿼리 실행에 필요한 데이터 및 메타데이터를 메모리에 캐시해두었다가 연결이 끊기면 날려버리므로, 작은 쿼리를 여러번 실행시켜야 하는 경우에는 connection을 유지하는 것이 성능에 좋다.
보통은 하나의 connection만 사용하는 것이 좋지만 connection pool을 만들어 여러 connection들을 사용하는 것도 가능하다. DuckDB는 이미 각 쿼리를 실행시키기 위해 병렬성을 충분히 활용하도록 설계되어 있지만, 모든 케이스에 대해 병렬 처리를 적용하는 것은 불가능하다. 따라서 만약 CPU 사용률이 널널하고, 네트워크 전송 속도 등이 병목의 원인이라면 여러 connection을 만들어 동시성을 확보하는 것도 도움이 될 것이다.
팁) Python에서 사용되는 DuckDBPyConnection은 thread-safe하지 않다. 또한 single connection을 사용하더라도 쿼리가 실행되는 동안 lock이 걸린다. 따라서 multi-thread 환경에서서 데이터베이스에 접근하기 위해서는 위해서는 .cursur() 메서드를 호출해 각 thread마다 cursor를 만들어 주어야 한다.
5. Extension
DuckDB는 쉬운 설치를 위해서 외부 의존성 없이 C++로 구현되어 있다. 따라서 추가적인 기능일 사용하기 위해서는 3rd-party extension을 설치하여 사용해야 한다.
최근 추가된 Vector Similarity Search(VSS) 기능을 예로 들자면, DuckDB에서 HNSW 알고리즘을 사용하려면 다음과 같은 세팅이 필요하다.
1
2
INSTALL vss;
LOAD vss;
그러면 Array of floats 타입의 컬럼에 그래프 기반의 인덱스를 추가할 수 있다.
1
2
CREATE TABLE embeddings (vec FLOAT[128]);
CREATE INDEX idx ON embeddings USING HNSW (vec);
한편, HTTPFS extension을 이용하면 데이터 네트워크 및 클라우드 스토리지를 더 잘 활용할 수 있다.
우선 extension을 설치하고 로딩하면
1
2
INSTALL httpfs;
LOAD httpfs;
다음 쿼리로 HTTPS와 replacement scan을 통해 온라인에 업로드된 parquet 파일을 읽어올 수 있다.
1
SELECT * FROM 'https://duckdb.org/data/holdings.parquet';
또는 ATTACH 구문을 통해 read-only 데이터베이스를 선언하는 것도 가능하다.
1
ATTACH 'https://blobs.duckdb.org/databases/stations.duckdb' AS stations_db (READ_ONLY);
1
2
SELECT count(*) AS num_stations
FROM stations_db.stations;
혹은 AWS S3에 접근하여 S3 Bucket 내 파일을 데이터베이스 경로로 선언할 수 있다. 이때 AWS credential 인증이 필요하다.
1
ATTACH 's3://duckdb-blobs/databases/stations.duckdb' AS stations_db (READ_ONLY);
Practice
Install
Python 환경에서 DuckDB를 설치하는 방법은 매우 간단하다. 터미널에서 pip 명령어를 통해 한번에 설치할 수 있다.
1
pip install duckdb
Python
그리고 다음 스크립트를 실행하면 테스트용 CSV 파일을 불러와 테이블을 만들어준다.
1
2
3
4
5
6
7
8
9
10
11
import duckdb
conn = duckdb.connect(":memory:")
conn.execute(
"""
CREATE OR REPLACE TABLE flights AS
FROM 'https://duckdb.org/data/flights.csv';
"""
)
conn.sql("SELECT * FROM flights")

UDF
DuckDB 또한 여느 라이브러리와 마찬가지로 사용자 정의 함수를 지원한다. 다음과 같이 Python 함수를 등록해주면 SQL에서 사용 가능하다.
1
2
3
4
5
6
7
from duckdb import typing as T
def lower(char: str) -> str:
return char.lower()
conn.create_function("custom_lower", lower, [T.VARCHAR], T.VARCHAR)
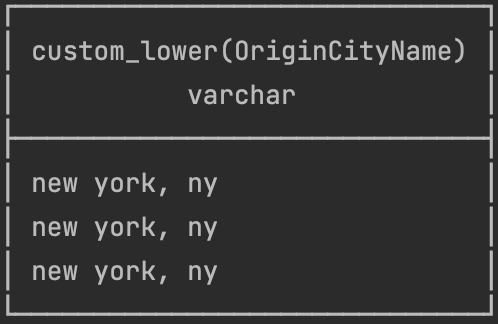
conn.sql("SELECT custom_lower(OriginCityName) FROM flights")
하지만 이 방법은 Python의 GIL에 의해 병렬적으로 실행되지 못한다. 또 DuckDB의 백엔드가 각 row마다 파이썬 인터프리터의 함수를 호출하는데에 분명 오버헤드가 발생할 것이다. 따라서 가능하다면 PyArrow 라이브러리를 활용하여 Vectorization 해주자.
1
2
3
4
5
6
7
8
9
from duckdb import typing as T
import pyarrow as pa
import pyarrow.compute as pc
def lower(chars: list[str]) -> list[str]:
return pc.utf8_lower(chars)
conn.create_function("vectorized_lower", lower, [T.VARCHAR], T.VARCHAR, type="arrow")
conn.sql("SELECT vectorized_lower(OriginCityName) FROM flights")

고찰
컴퓨터 과학 분야에서, 특히 ML 쪽에서 데이터 전-후처리 할 때, DuckDB는 Pandas를 대체할 수 있을 거라 본다. 그렇게 생각하는 이유는 다음과 같다.
- DuckDB는 Pandas보다 컴퓨팅 리소스를 효율적으로 사용한다.
- Tensorflow, Torch 등 ML 프레임워크를 사용할 때 Apache Arrow를 중심으로 in-memory에서 데이터를 zero copy할 수 있다.
- DuckDB는 분산(수평적 확장) 환경에 적합하지 않다. 하지만 GPU가 달린 서버는 보통 CPU와 메모리 자원이 넉넉하기 때문에 DuckDB를 사용하기에 최적의 조건이다.