Dive into Flink (3)
지난 글에 이어 이번에는 Apache Flink가 지원하는 SQL API를 사용해보려 한다.
이전 글부터 계속 Scala + SBT 조합으로 Flink Application을 구현하고 있었으나, Flink가 Scala만을 위한 별도의 API를 더 이상 지원하지 않겠다고 언급한 사실을 알게되었다. (2.x 버전부터 적용될 예정)
따라서 Scala 용 의존성을 모조리 걷어내고 Java 용 의존성으로 교체하는 작업을 먼저 진행하였다. 이후 꼭 필요한 의존성만 추려내면 다음과 같다.
1
2
3
4
5
6
7
8
libraryDependencies ++= Seq(
"org.apache.flink" % "flink-streaming-java" % flinkVersion % "provided",
"org.apache.flink" % "flink-table-api-java" % flinkVersion,
"org.apache.flink" % "flink-table-api-java-bridge" % flinkVersion % "provided",
"org.apache.flink" % "flink-table" % flinkVersion % "provided" pomOnly(),
"org.apache.flink" % "flink-connector-kafka" % "1.17.2" % "provided",
"org.apache.flink" % "flink-shaded-guava" % "30.1.1-jre-16.1"
)
Practice
다음 Github 링크에 설정들을 상세하게 정리해 두었습니다.
Kafka Producer
지난 글과는 달리 실제와 비슷한 메시지를 Kafka로 전송하기 위해 FastAPI로 간단한 서버를 개발하였다. 사용자들이 영화에 평점을 매기면 이 평점 이벤트를 Kafka로 전송하는 상황을 가정하여 MovieLens 데이터를 사용하였다.
먼저 pydantic을 이용해 DTO를 정의해준다.
1
2
3
4
5
class Rating(BaseModel):
user_id: int = Field(..., alias="user_id")
movie_id: int = Field(..., alias="movie_id")
rating: float = Field(..., alias="rating")
timestamp: int = Field(..., alias="timestamp")
이후 클라이언트에서 REST API 콜을 받으면 이를 Kafka로 넘겨주는 kafka producer를 구현한다.
1
2
3
4
5
6
7
8
9
10
11
TOPIC = "input.flink.dev"
@router.post("/rating")
def send_message(
rating: Rating,
producer: Annotated[KafkaProducer, Depends(get_kafka_producer)]
) -> Rating:
payload = rating.model_dump(by_alias=False)
producer.send(topic=TOPIC, value=payload)
producer.flush(100)
return rating
FastAPI의 경우에는 짧은 코드로도 application 구현 및 docker container로의 배포가 가능하다. 이번에는 8082 포트를 사용해보자.
1
2
3
4
5
6
7
8
kafka-producer:
container_name: kafka-producer
build:
dockerfile: ./docker/producer/Dockerfile
image: kafka-producer
ports:
- "8082:8082"
command: "uvicorn app.main:app --host 0.0.0.0 --port 8082"
localhost:8082/docs으로 swagger에 접속하여 테스트도 해볼 수 있다.
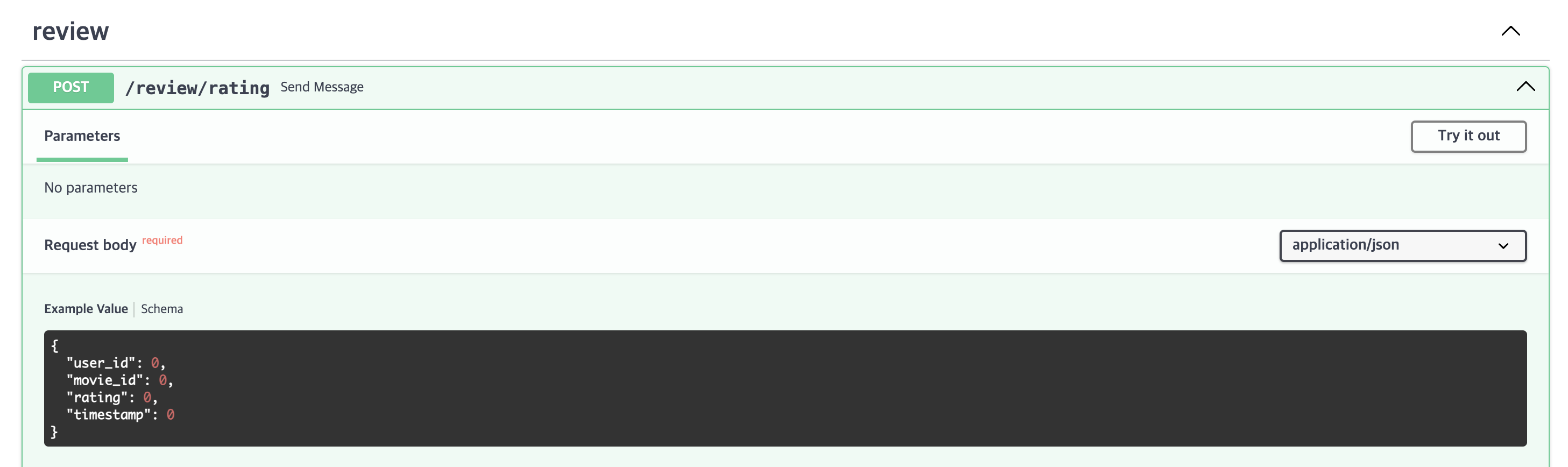
다음은 MovieLens 데이터를 다운로드하고 난 후, pandas로 읽어 자동으로 request를 날리는 파이썬 스크립트를 작성한다. 이 스크립트를 실행하면 JSON format의 평점 데이터가 kafka broker로 전송된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
if __name__ == "__main__":
load_data("/tmp/flink/dataset")
rating_df = pd.read_csv("/tmp/flink/dataset/ratings.csv").sort_values("timestamp")
url = "http://localhost:8082/review/rating"
headers = {"accept": "application/json"}
for user_id, movie_id, rating, timestamp in rating_df.itertuples(index=False):
payload = dict(
user_id=int(user_id),
movie_id=int(movie_id),
rating=float(rating),
timestamp=int(timestamp),
)
response = requests.post(url=url, data=json.dumps(payload), headers=headers)
print(response.status_code)
Flink SQL API
스트리밍 애플리케이션 구현 시 SQL API를 이용하면 데이터 소스와 필드 구조를 간단한 쿼리 구문으로 선언할 수 있었다. Table API의 StreamTableEnvironment 객체를 생성하고 SQL를 통해 커넥터 및 Serde를 구성해주면 Dataset에 비해 코드를 간결하게 쓸 수 있다.
1
2
3
4
5
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
아래의 코드처럼 전송 받을 메시지의 필드와 커넥터, format 등을 table property로 구성할 수 있다. 데이터를 받아올 source와 데이터를 넘겨줄 sink 각각 테이블을 생성해야 한다.
source table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
tableEnv.executeSql(
"""
| CREATE TABLE ratings (
| user_id INT,
| movie_id INT,
| rating FLOAT,
| `timestamp` BIGINT
| ) WITH (
| 'connector' = 'kafka',
| 'topic' = 'input.flink.dev',
| 'properties.bootstrap.servers' = 'kafka:9092',
| 'properties.group.id' = 'flink',
| 'properties.auto.offset.reset' = 'latest',
| 'format' = 'json'
| )
|""".stripMargin
)
sink table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
tableEnv.executeSql(
"""
| CREATE TABLE ratings_clean (
| user_id INT,
| movie_id INT,
| rating FLOAT,
| created_at STRING
| ) WITH (
| 'connector' = 'kafka',
| 'topic' = 'output.flink.dev',
| 'properties.bootstrap.servers' = 'kafka:9092',
| 'format' = 'json'
| )
|""".stripMargin
)
이렇게 테이블들을 생성한 후 스트리밍 처리 로직을 SQL로 작성하여 실행시켜준다. 그러면 선언된 로직을 따라 Flink가 스트리밍 처리를 하게 된다. 아래는 단순히 unix timestamp를 datetime으로 바꾸어주는 로직이다.
1
2
3
4
5
6
7
8
9
10
11
tableEnv.executeSql(
"""
| INSERT INTO ratings_clean
| SELECT
| user_id,
| movie_id,
| rating,
| FROM_UNIXTIME(`timestamp`) AS created_at
| FROM ratings
|""".stripMargin
)
컴파일 후 Jar를 업로드하고 Job을 실행하면, 테이블 Web UI에서 아래와 같은 실행 계획을 볼 수 있다.
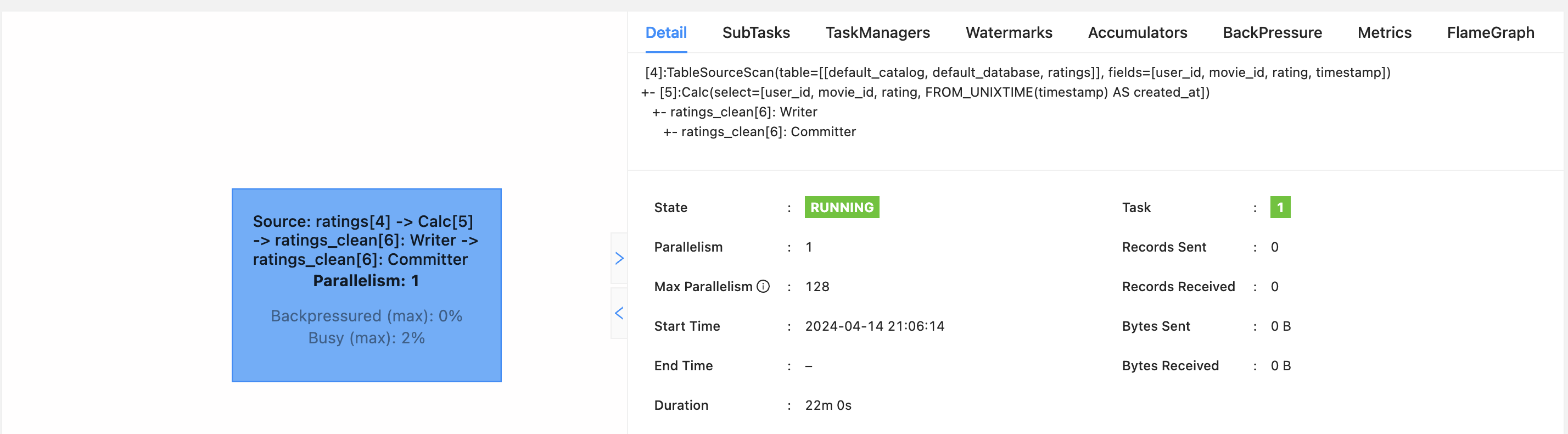
이전 글과 마찬가지로 Job이 잘 실행되고 있는지 확인해 볼 수 있다. 위에서 작성한 파이썬 스크립트를 통해 데이터를 API 서버로 붓고, 콘솔에서 Flink에 의해 데이터가 처리되기 전과 후를 살펴보도록 하자.
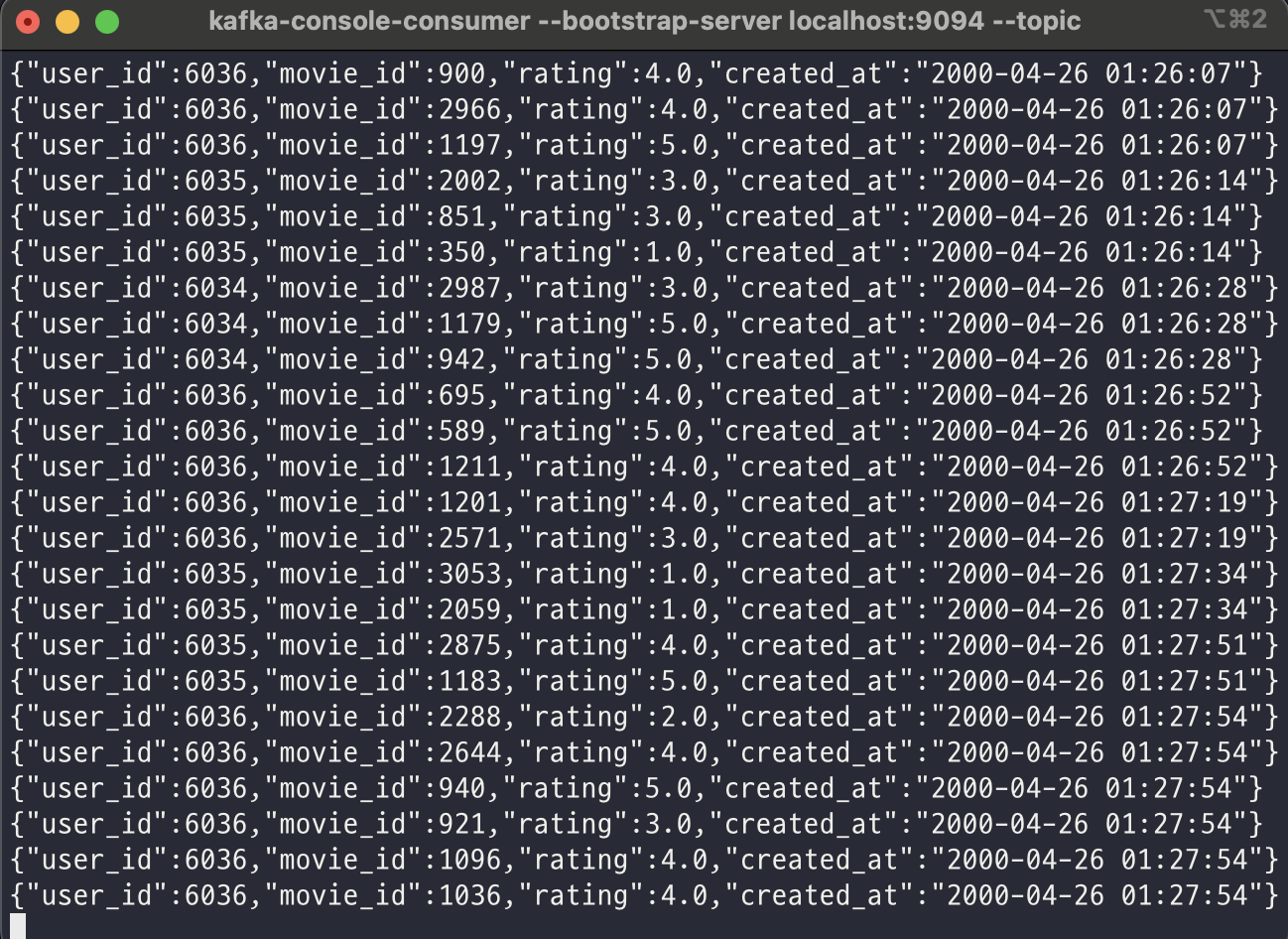
input.flink.dev
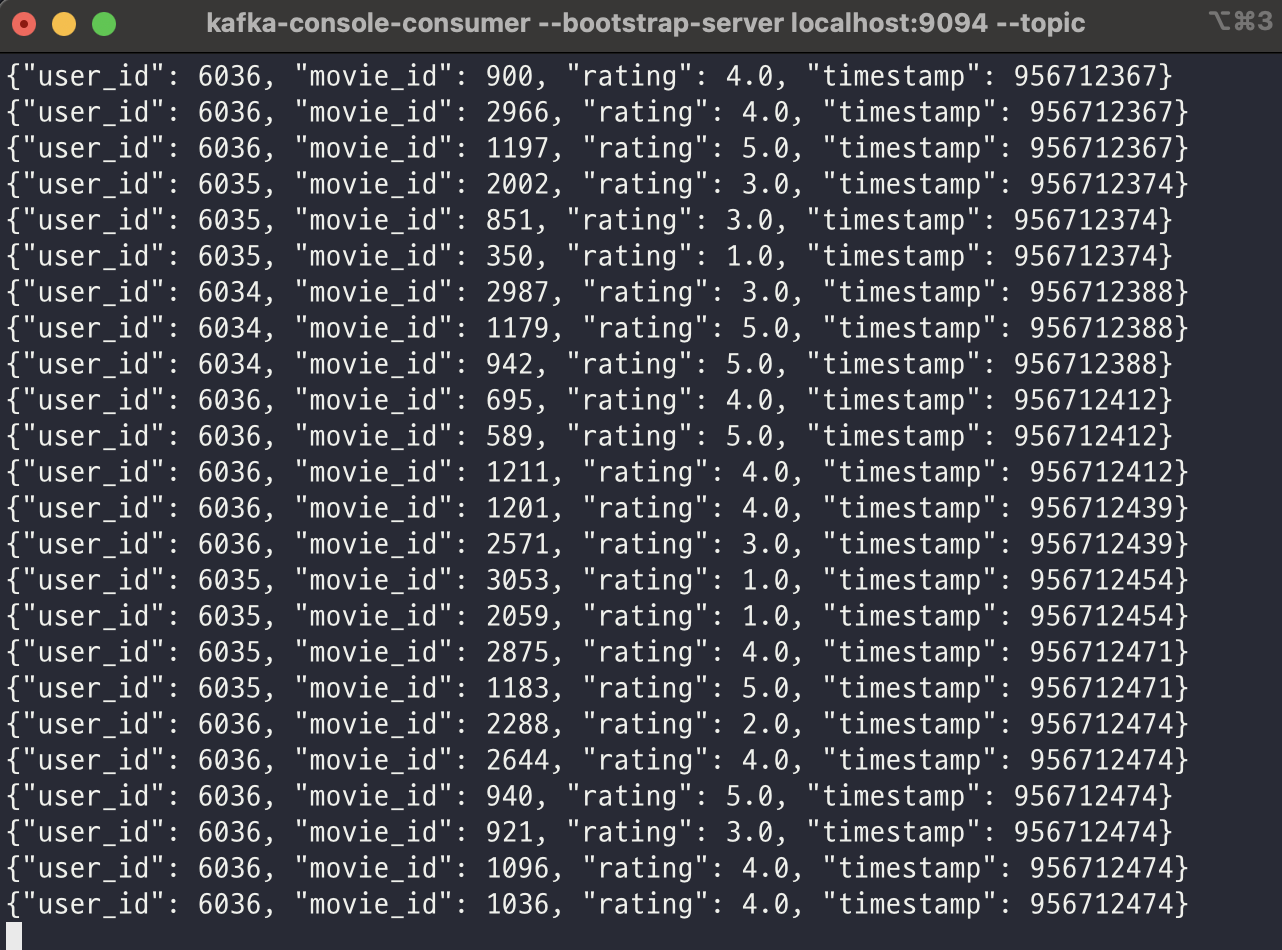
Flink Application을 거치면서 메시지의 필드가 timestamp에서 created_at으로 변경된 것을 확인할 수 있다.
output.flink.dev