Dive into Flink (2)
이전 글에 이어 이번에는 Apache Flink를 띄우고 테스트해보려고 한다. Kafka와 Flink를 Docker Container에 배포한 후 간단한 Job을 제출하여 스트리밍 애플리케이션이 잘 작동하는지 확인해볼 예정이다.
Practice
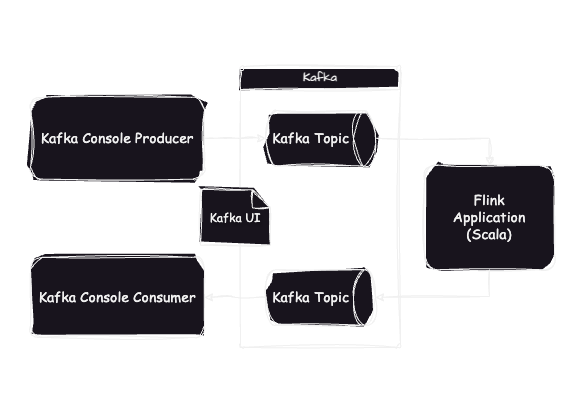
최소한의 구현으로 Flink를 테스트하기 위해서 다음과 같이 시스템을 구성하였다.
- Kafka 메시지의 발행과 구독은 콘솔을 이용한다.
- Kafka topic 및 consumer group 생성은 Kafka UI를 통해 확인한다.
- Flink 애플리케이션은 Scala로 구현한다.
Docker Setting
다음 Github 링크에 설정들을 상세하게 정리해 두었습니다.
Kafka
메시지 큐로는 Flink와 함께 가장 많이 사용되는 Apache Kafka를 선택하였다. 실습에선 분산 환경이 필요없으므로 1개의 브로커만 구성하였고, zookeeper를 별도로 띄우지 않기 위해 KRaft 사용이 가능한 3.4.1 버전을 선택하였다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
kafka:
container_name: kafka
image: bitnami/kafka:3.4.1
ports:
- "9094:9094"
environment:
# KRaft settings
KAFKA_CFG_NODE_ID: 0
KAFKA_CFG_PROCESS_ROLES: controller,broker
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 0@kafka:9093
# Listeners
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER
volumes:
- ./docker/volume/kafka:/bitnami/kafka
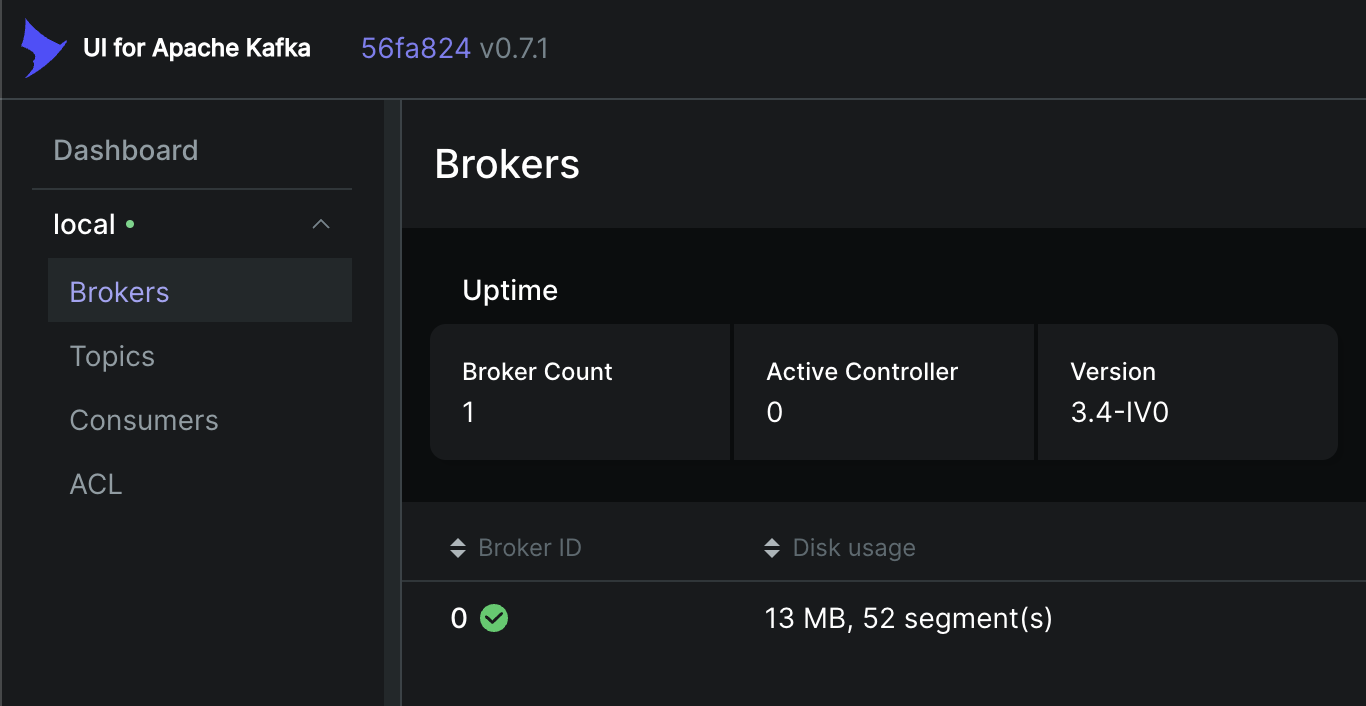
Kafka UI
브로커를 모니터링하고 토픽을 간편하게 제어하기 위해서 Kafka UI를 사용하였다. 이때 DYNAMIC_CONFIG_ENABLED를 활성화하여 클러스터 등록/제거를 편리하게 할 수 있었다.
1
2
3
4
5
6
7
8
9
10
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8080:8080"
restart: always
environment:
- DYNAMIC_CONFIG_ENABLED=true
volumes:
- ./docker/kafka-ui/config.yml:/etc/kafkaui/dynamic_config.yaml
localhost:8080에 접속하면 Kafka UI를 확인할 수 있다.
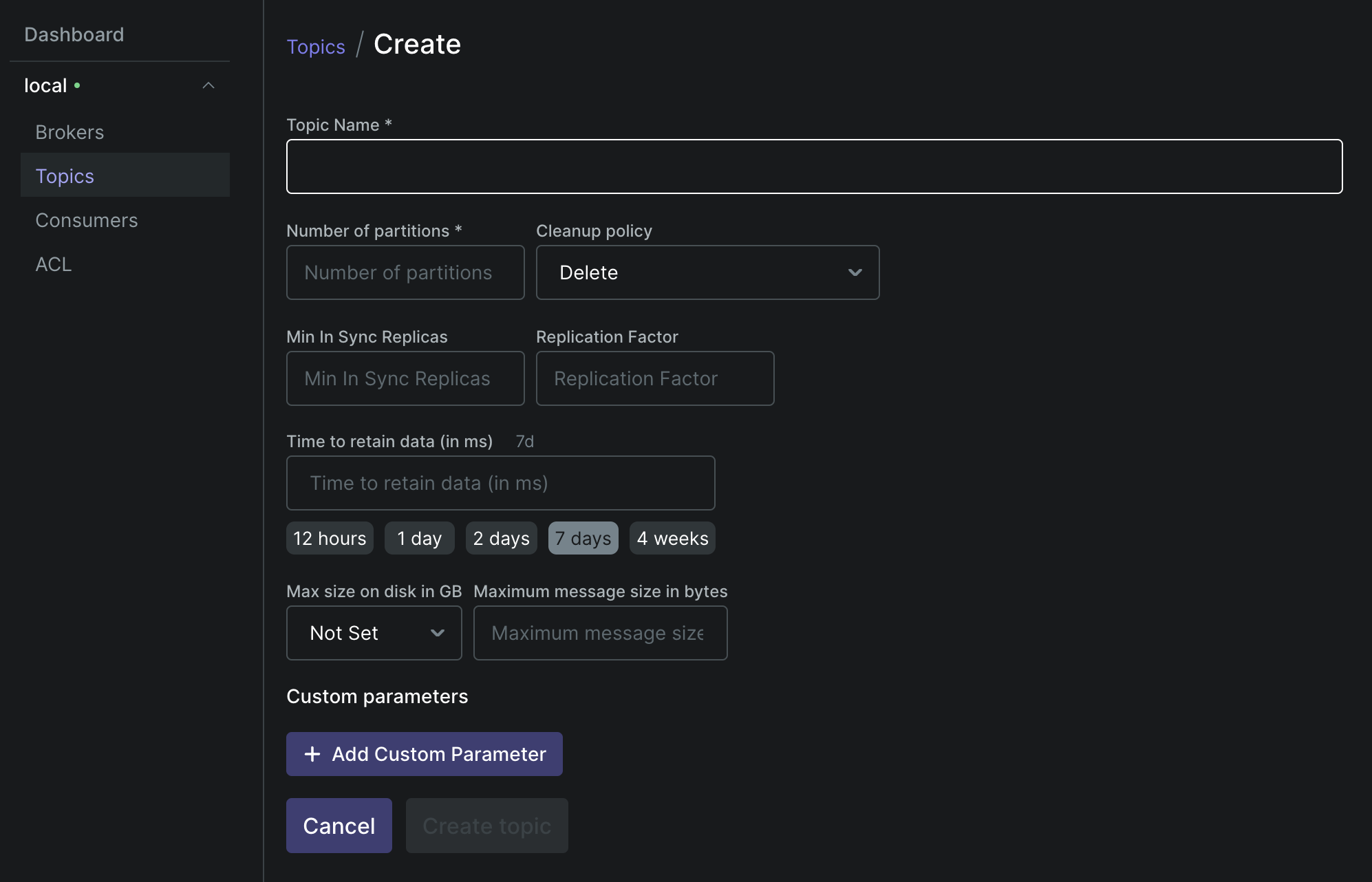
Dashboard에서 Topics » Add a Topic 버튼을 클릭하면 새로운 토픽을 생성할 수 있다. Partition 및 Replica 개수는 대충 1개로 설정하였으며, Flink 애플리케이션의 input과 output을 구별하기 위해 토픽은 2개를 생성하였다.
- input.flink.dev
- output.flink.dev
Flink
Flink는 Job Manager와 Task Manager 역할을 하는 컨테이너를 각각 따로 배포하였다. 이때 Job Manager의 8081 port를 뚫어주어 Flink Dashboard에 접근 가능하도록 만든다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
flink-jobmanager:
container_name: flink-jobmanager
hostname: flink-jobmanager
build:
dockerfile: ./docker/flink/Dockerfile
image: flink-dev
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=flink-jobmanager
volumes:
- ./docker/volume/flink/jobmanager:/data/flink
flink-taskmanager:
container_name: flink-taskmanager
hostname: flink-taskmanager
build:
dockerfile: ./docker/flink/Dockerfile
image: flink-dev
command: taskmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=flink-jobmanager
volumes:
- ./docker/volume/flink/taskmanager:/data/flink
Flink 공식 이미지 뿐만아니라 Scala 및 Kafka 관련 의존성을 추가할 필요가 있다. 따라서 별도의 Dockerfile을 만들어 의존성을 구성하고 yaml 파일에서 빌드할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
FROM flink:1.18.1-scala_2.12-java11
RUN curl -L https://repo1.maven.org/maven2/org/apache/flink/flink-streaming-scala/1.18.1/flink-streaming-scala-1.18.1.jar \
-o ${FLINK_HOME}/lib/flink-streaming-scala-1.18.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.17.2/flink-connector-kafka-1.17.2.jar \
-o ${FLINK_HOME}/lib/flink-connector-kafka-1.17.2.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.4.1/kafka-clients-3.4.1.jar \
-o ${FLINK_HOME}/lib/kafka-clients-3.4.1.jar
RUN curl -L https://repo1.maven.org/maven2/org/apache/flink/flink-shaded-guava/30.1.1-jre-16.1/flink-shaded-guava-30.1.1-jre-16.1.jar \
-o ${FLINK_HOME}/lib/flink-shaded-guava-30.1.1-jre-16.1.jar
Flink Job Manager를 띄우는데 성공했다면 localhost:8081에 접속하여 Task Manager 상태를 확인할 수 있다.
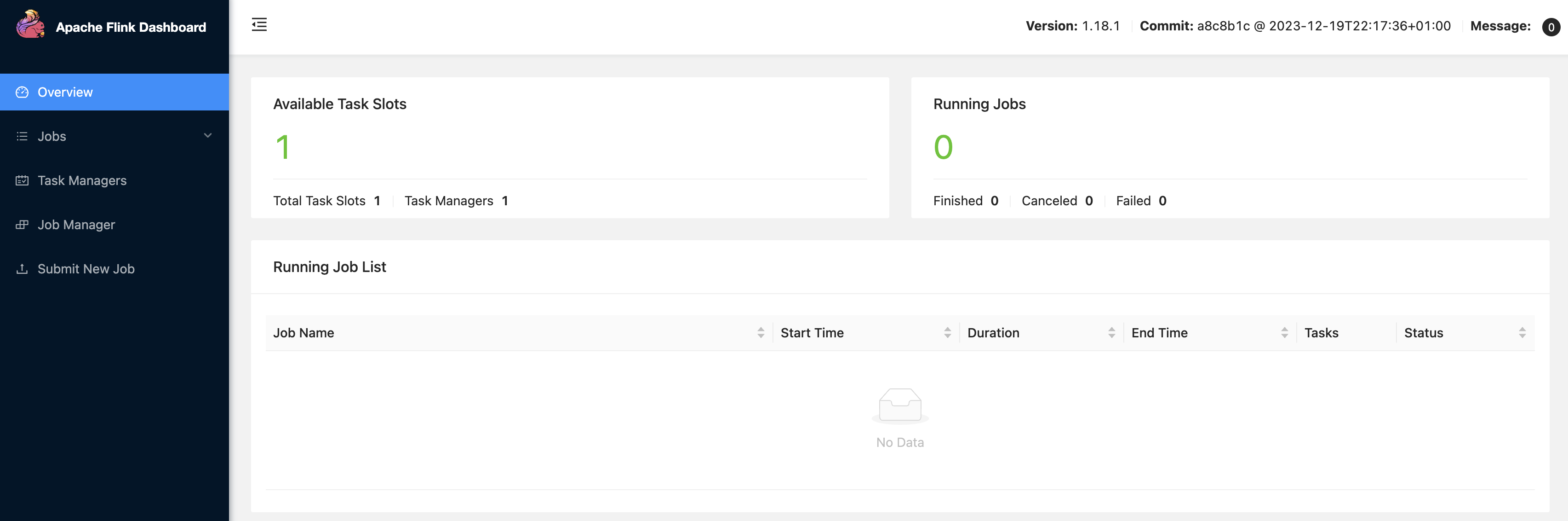
Applications
이제 Flink Application을 구현하고 제출해보자. PyFlink 대신 데이터 엔지니어에게 좀 더 익숙한(?) Scala를 사용하였는데 생각보다 레퍼런스가 부족해 애를 먹었다. 후 너넨 이런거 피지 마라
flink-connector-kafka 의존성의 KafkaSource, KafkaSink를 이용하면 애플리케이션을 쉽게 구현할 수 있다. Consumer group 설정에 필요한 property들도 빌더 패턴을 통해 주입할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
object Job {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val kafkaSource = KafkaSource.builder()
.setBootstrapServers("kafka:9092")
.setTopics("input.flink.dev")
.setGroupId("flink-consumer-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.setProperty("enable.auto.commit", "true")
.setProperty("auto.commit.interval.ms", "1")
.build()
val kafkaSink = KafkaSink.builder()
.setBootstrapServers("kafka:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic("output.flink.dev")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build()
val streamLines = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Sink")
streamLines.print()
streamLines.sinkTo(kafkaSink)
env.execute("Flink Streaming Scala Example")
}
}
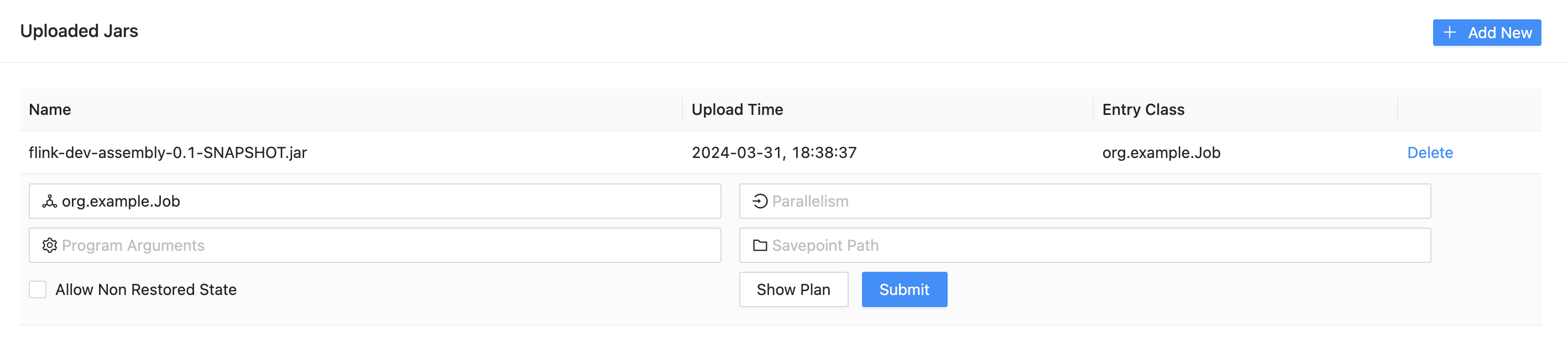
Sbt를 이용해 컴파일한 후, API를 호출하여 jar 파일을 Job Manager로 업로드 해준다. Flink Dashboard의 Submit New Job » Add New 버튼을 클릭하여 메뉴얼하게 업로드하는 것도 가능하다.
1
2
sbt clean assembly
curl -X POST http://localhost:8081/v1/jars/upload -H "Expect:" -F "jarfile=@./target/scala-2.12/flink-dev-assembly-0.1-SNAPSHOT.jar"
Jar 파일을 업로드하면 다음과 같이 Job을 제출할 수 있다. 실행시킬 entrypoint를 기입하고 Submit 버튼을 누르면 Job이 실행된다. 마찬가지로 메뉴얼하게 실행하는 대신 REST API를 사용할 수도 있다.
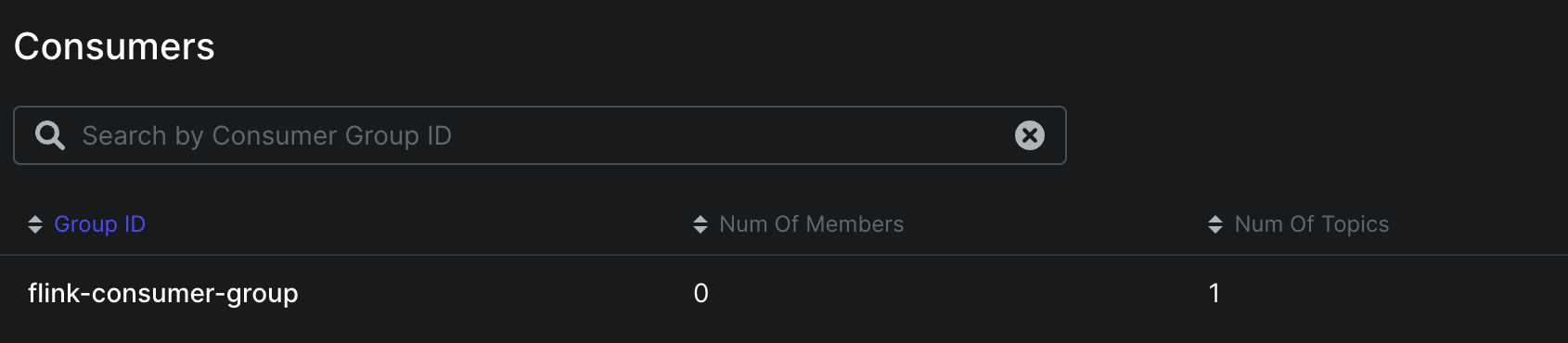
Kafka와 통신에 성공하면 Kafka UI에서 consumer group이 잘 등록되었는지 확인할 수 있다.
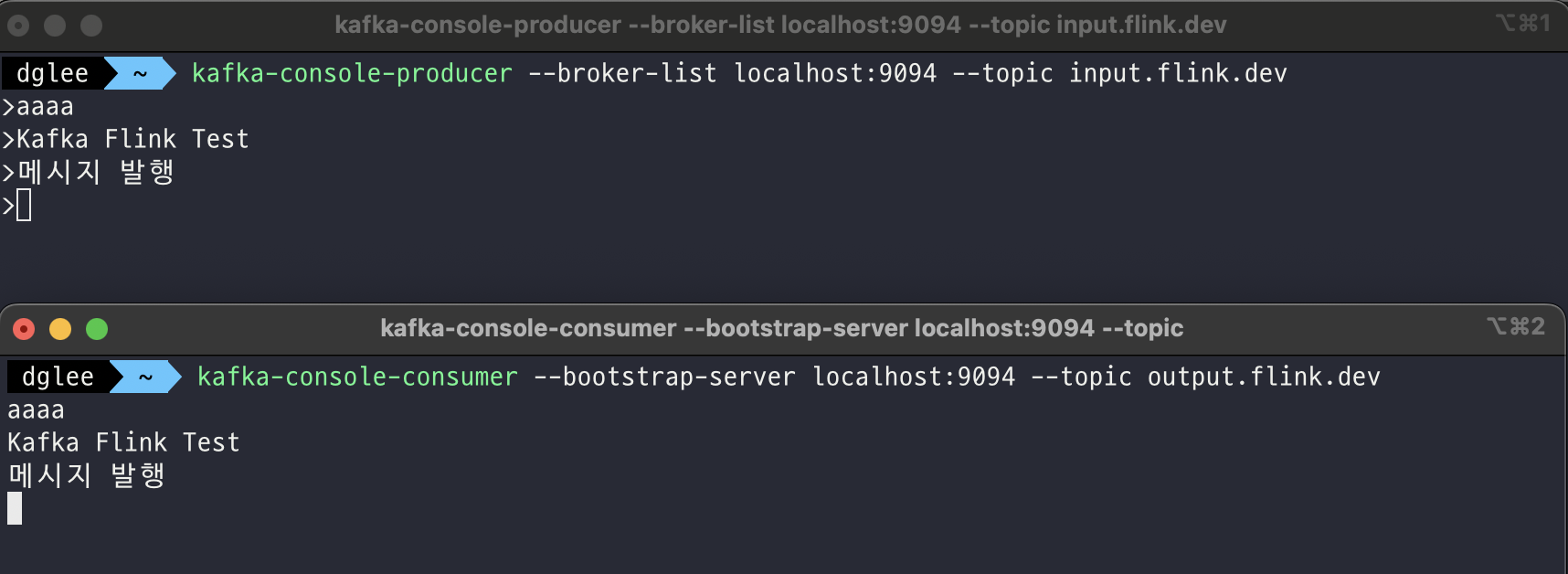
이제 콘솔로 Kafka Producer와 Consumer를 띄워 메시지가 잘 전달되는지 살펴보자. 테스트는 로컬에서 진행하였으며, input과 output 토픽을 분리하여 Flink Application이 잘 동작하는지 확인하였다.
Kafka console producer
1
kafka-console-producer --broker-list localhost:9094 --topic input.flink.dev
Kafka console consumer
1
kafka-console-consumer --bootstrap-server localhost:9094 --topic output.flink.dev
약간의 지연시간은 존재하지만 다른 토픽으로 메시지가 무사히 전달되는지 확인할 수 있었다.