Dive into Flink (1)
최근 팀에서 특정 상품을 추천에 노출시키기 위해 파이프라인을 구축할 일이 있었다. Kafka에서 이벤트를 받아와 API를 호출한 후 Hive에 적재해야 했는데, streaming 처리가 적절하다고 판단했음에도 불구하고 batch 처리로 구현하였다.
팀 내 데이터 엔지니어가 나뿐이라 클러스터 환경의 High Availability(HA) 유지가 부담되기도 하고, 이전에 Spark Structured Streaming을 위해 long-running EMR을 관리하면서 좋지 않은 기억이 많았다. 주말에 클러스터가 죽는 경험은 진짜 최악이었다.
그런데 마침 조직에서 Apache Flink를 도입해보자는 말이 나왔다. 만약 이 파이프라인을 Flink로 이관시킨다면 좀 더 깔끔할 것 같다는 생각이 들었다. 지금 당장은 아니라도 언젠가 Flink를 쓸 것 같아 이번 기회를 빌어 깊게 공부해 두려고 한다.
Flink
Apache Flink는 배치 및 스트림을 지원하는 stateful 처리를 위한 분산 처리 프레임워크이다. 클러스터 환경에서 실행 가능하도록 High Availability(HA) 및 Scalability에 중점을 두어 설계되었으며, 인메모리 계산을 수행하여 지연 시간(latency)이 낮고 성능이 뛰어난 편이다.
공식 홈페이지에서는 Flink의 사용처로 크게 다음 3가지를 소개하고 있다.
1. Event Driven Application
이벤트 기반으로 데이터를 처리하기 위한 용도이다. 이벤트가 발생하여 읽어야할 메시지가 생기면 스트림 처리를 수행한다. 여러 이벤트를 읽어와 새로운 이벤트를 발생시킬 수도 있고, 이상치가 탐지되면 외부로 알람을 보낼 수도 있다.
아마 가장 많이 함께 사용되는 프레임워크로는 Kafka가 있을 것 같다. Kafka Topic에 새 메시지가 들어오면 이를 Consume하여 데이터를 처리한 후, 새로운 메시지를 Kafka에 Produce한다. 이 과정에서 Flink는 Kafka의 transaction 기능과 연계하여 End-to-End Exactly-Once 처리를 보장해준다.
2. Stream & Batch Analysis
Flink는 데이터로부터 인사이트를 추출하고 분석하기 위한 방법으로 배치 쿼리 뿐만 아니라 실시간 쿼리 또한 지원하고 있다. 데이터가 지속적으로 추가되거나 업데이트되는 중에도 사용자는 Table API 또는 SQL를 통해 데이터를 조회할 수 있다.
3. Data Pipelines & ETL
가장 일반적인 사용 사례로, 여러 소스에서 데이터를 가져와 처리한 후, 그 결과를 다른 데이터 스토리지에 적재하는 파이프라인에 Flink를 사용할 수 있다. 프로세스에서 지속적으로 스트림 처리를 수행하여 짧은 지연 시간을 유지할 수 있고, state를 저장 및 호출할 수 있어 과거 이벤트에 의존 가능한 파이프라인도 구현할 수 있다.
Architecture
Flink에서 스트리밍 애플리케이션을 실행시키기 위해서는 리소스 매니저가 필요하다. 리소스 매니저로는 Apache Spark와 흡사하게 Hadoop YARN 또는 Kubernetes를 사용할 수 있으며, Stand Alone로도 실행 가능하다.
Structure
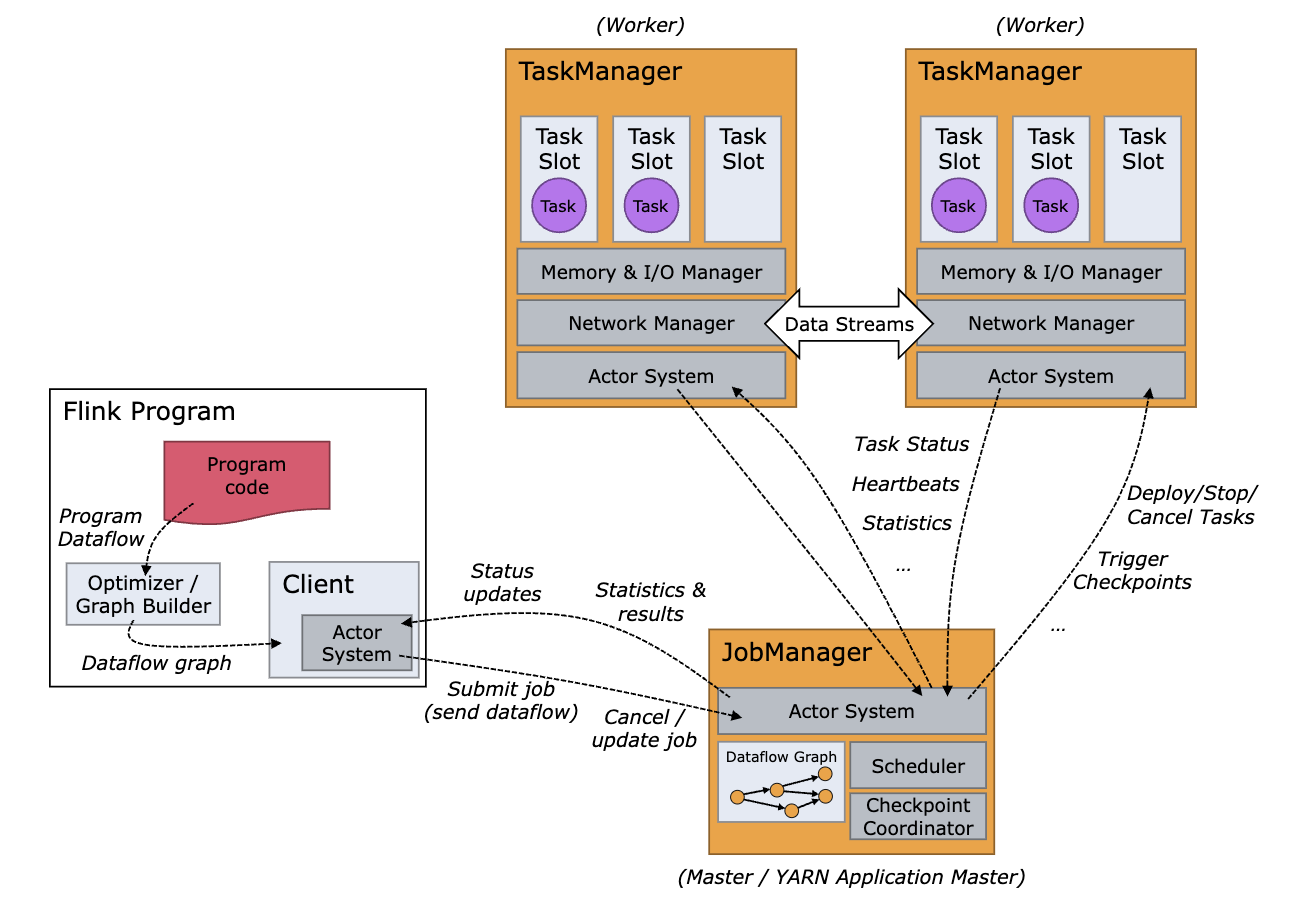
Client가 Flink Application으로 Job을 제출하면 Dataflow Graph가 생성되어 Job Manager에게 전달된다.
Flink는 크게 두 JVM 프로세스로 나뉜다.
1. Job Manager
Job Manager는 스케쥴러와 체크포인트를 조정할 뿐만 아니라, 애플리케이션이 분산되어 실행될 수 있도록 다양한 역할을 수행하게 된다. Job 실행을 위해서는 최소 하나 이상이 필요하며, HA 구성이 필요하다면 둘 이상으로 운영될 수 있다.
Resource Manager
- 클러스터에서 리소스를 할당, 해제 및 프로비저닝을 담당한다. Task Manager가 사용할 가장 작은 리소스 단위인 “Task Slot”을 관리한다.
Job Master
- 각 Job마다 생성되며, 대응되는 Dataflow Graph가 실행되도록 명령을 내리고 모니터링한다.
Dispatcher
- Client가 Job을 제출할 수 있도록 REST 인터페이스를 제공하며, Job이 제출될 때마다 새로운 Job Master를 생성한다. 또한 Flink WebUI를 실행하여 Job에 대한 정보를 제공한다.
2. Task Manager
Task Manager는 Dataflow의 Task들을 실행하고, 필요에 따라 Task Manager끼리 데이터를 교환하기도 한다. Job Manager와 마찬가지로 최소 하나 이상이 필요하다.
하나의 Task가 실행되기 위해서는 적어도 하나의 Task Slot이 필요하다. Task Manager는 여러 Task Slot을 가지고 있는데, 하나의 Task Slot이 곧 하나의 동시성 단위이다. 만약 둘 이상의 Task Slot을 갖고 있다면 동시에 둘 이상의 Task를 처리할 수 있다.
Task & Operator Chain
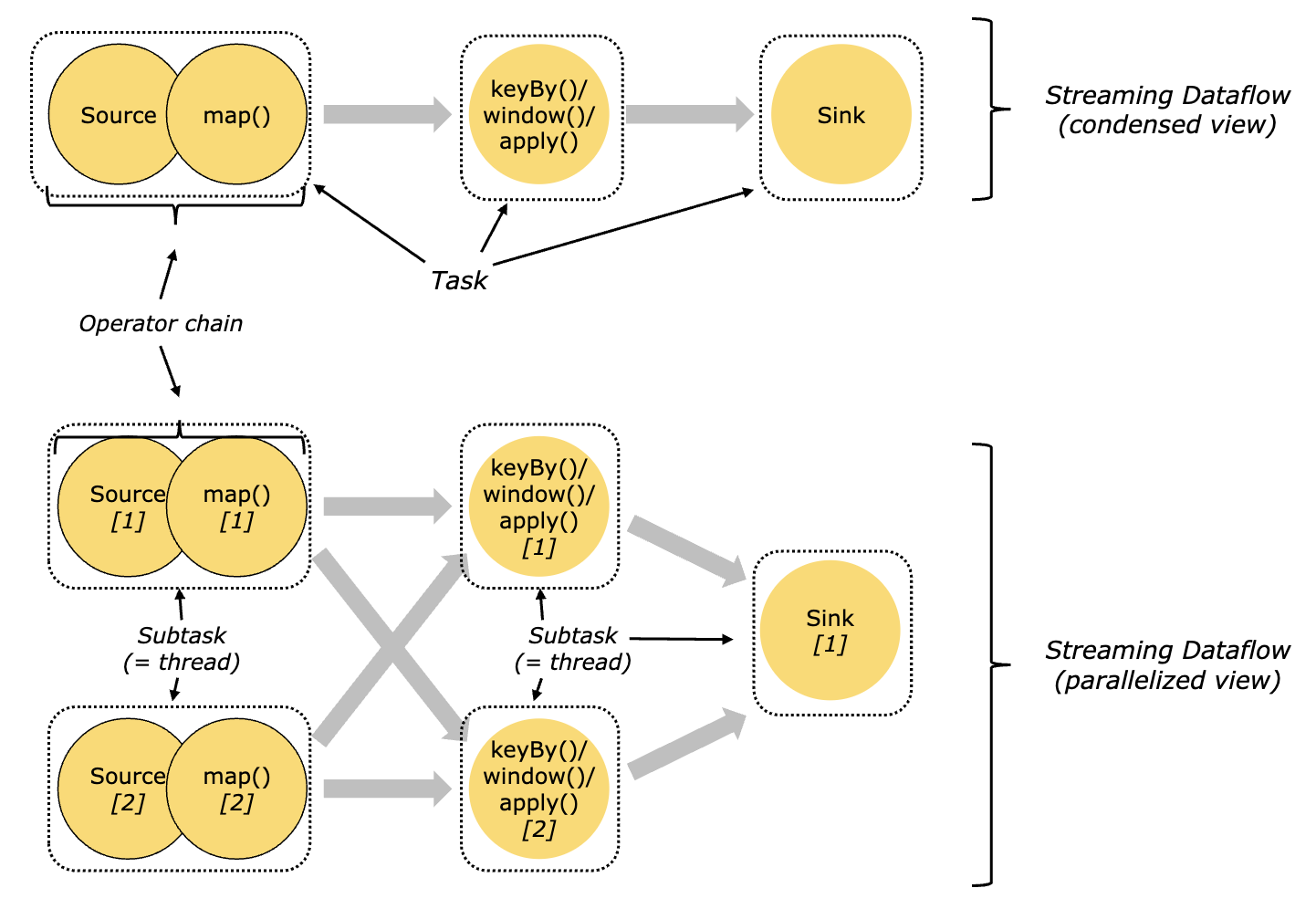
Dataflow Graph가 Physical Graph로 전환되면 여러 Operator가 하나의 chain에 묶여 Task에 대응될 수 있다. 그리고 하나의 Task는 한 개의 thread에 의해 처리된다. 즉, 가능한 하나의 thread에서 처리될 수 있는 Operator들은 chain에 묶여 하나의 Task로 취급한다.
| Logical | Physical |
|---|---|
| Dataflow Graph | Physical Graph |
| Operator Chain | Task |
| Operator | Subtask |
이미 익숙하게 알고 있는 Spark의 개념과 대응시키면 다음과 같다.
| Flink | Spark |
|---|---|
| Job Manager | Spark Driver |
| Task Manager | Spark Executor |
| Task Slot | Spark Core |
| Flink Application | Spark Application |
| Job | Job |
| Task | Stage |
| Subtask | Task |
Task Slot & Slot Sharing
Task Manager는 각 Thread 마다 하나 이상의 Subtask를 실행시킬 수 있다. 이 때 하나의 Task Manager가 처리할 작업 수를 제어하기 위해서 Task Slot이라는 개념을 사용한다.
Task Slot은 Task Manager의 메모리 리소스를 사이 좋게 나누어 가진다. 만약 Task Manager가 3개의 Task Slot을 가지고 있다면, 각 Task Slot은 메모리 리소스를 가지고 경쟁할 필요 없이 1/3 씩 나누어 사용한다. (단, CPU 리소스에 대한 격리는 발생하지 않는다고 한다)
Task Slot을 늘리면 동시성을 증가시켜 데이터를 빠르게 처리할 수 있다. 또 동일한 JVM 내에서 작업이 이루어지기 때문에 TCP 연결 및 데이터 구조 등을 공유하여 오버헤드를 줄일 수 있다.
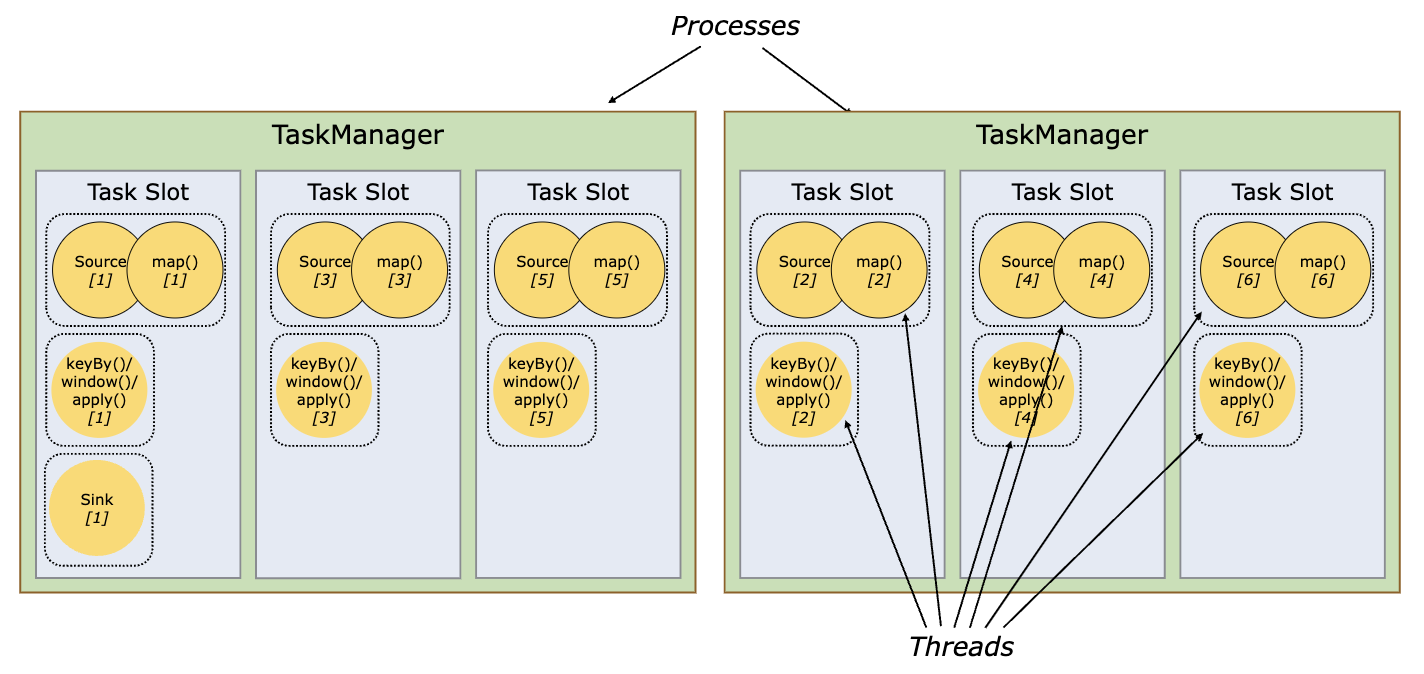
Flink에서는 서로 다른 Task의 Subtask라도 같은 Job이기만 하면 Task Slot을 공유할 수 있다. 그림의 가장 왼쪽 Task Slot 처럼 Job 파이프라인 전체 과정을 차지할 수도 있다. 이러한 공유에는 두 가지 주요 이점이 있다.
Flink Job을 수행할 때 총 몇 개의 Task가 필요로 할지 사전에 계산할 필요 없다. Job 수행에 필요한 최대 parallelism 개수 만큼 Task Slot을 할당하기만 하면 된다.
리소스 사용률을 높일 수 있다. 만약 Slot Sharing 없이 Slot
A에서는source/map()operator들만, SlotB에서는keyBy()operator들만 처리한다면 리소스 집약적 연산이 이루어지는 SlotB의 처리가 끝날때까지 SlotA의 리소스는 쉬게 된다. 따라서 Slot을 공유하여 무거운 Subtask들을 Slot들끼리 분배할 수 있으면 리소스를 더 잘 활용할 수 있게 된다.
Application Execution
Flink에서는 Job을 제출할 때 목적에 따라 서로 다른 방식으로 Flink Application을 실행시킬 수 있다. 이러한 방식들은 실제로 처리를 수행할 클러스터의 수명 주기 및 리소스 격리에 따라 구분된다.
Flink Application Cluster
Flink Application Cluster는 Client에서 Job을 제출할 필요 없이 클러스터 내부에서 단일 애플리케이션의 Job들을 실행시키는 방식이다. 즉, 클러스터는 특정 애플리케이션 실행만을 목적으로 프로비저닝되는 dedicated cluster이며, 애플리케이션 로직과 종속성이 담긴 JAR 파일을 패키징 해두면 클러스터의 entrypoint가 main() 메서드를 호출하여 패키지 속에서 JobGraph를 추출한다.
Life Cycle
- 클러스터 수명 주기 = 애플리케이션 수명 주기
Resource Isolation
- ResourceManager 및 Dispatcher는 단일 Flink Application으로 범위가 지정되어 Flink Session Cluster보다 문제를 더 효과적으로 격리할 수 있다.
Flink Session Cluster
Flink Session Cluster는 Client에서 여러 Job들을 제출하도록 허용하는 long-running 클러스터이다. 모든 Job이 완료되더라도 session이 중지될 때까지 클러스터와 Job Manager는 계속 실행된다.
Life Cycle
- 클러스터 수명은 Job의 수명에 독립적
Resource Isolation
- Task Manager 슬롯은 작업 제출 시 Resource Manager에 의해 할당되고 Job이 완료되면 해제된다. 모든 Job이 동일한 클러스터를 공유하기 때문에 클러스터 리소스 경쟁이 존재한다.
- 어떤 Task Manager에 충돌이 발생하면 그곳에서 실행 중인 모든 Job들이 실패한다. 즉, 어떤 Job이 한 Task Manager에 문제를 일으키면 다른 Job에 영향을 미칠 수도 있다.
Flink API
Flink는 streaming / batch 애플리케이션 개발을 위한 다양한 수준의 추상화를 제공하고 있다.
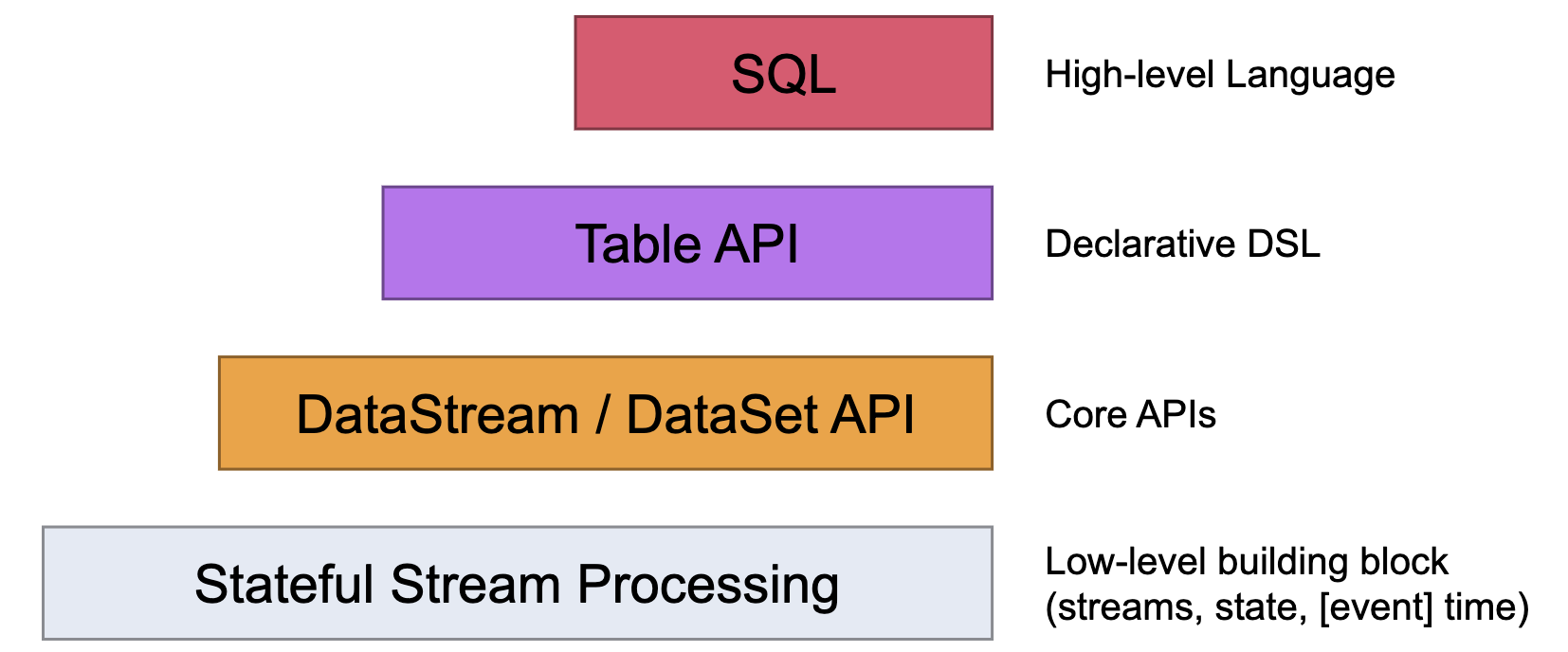
1. Stateful & Timely Stream Processing
이 수준에서 사용자는 State Backend를 통해 하나 이상의 스트림에서 이벤트를 자유롭게 처리할 수 있다. Checkpoint와 Savepoint를 이용하면 처리에 필요한 state를 일관적이고 내결함성 있게 다룰 수 있다. 또 Event Time과 Processing Time을 이용하면 더 정교한 로직을 구현할 수 있고 메시지 지연에 효과적으로 대응할 수 있다.
2. DataStream & DataSet API
Core API 인 DataStream API을 사용하면 UDF, aggregation, window 등 데이터 처리를 위한 요소들을 사용할 수 있다. Java 및 Scala 등의 프로그래밍 언어 형태로 제공된다.
DataSet API는 루프/반복이 필요한 경우처럼 bounded dataset를 처리하기 위한 추가적인 요소를 제공한다.
3. Table API
Table API는 테이블 기반의 선언적 DSL로, 스키마가 지정된 테이블이 어떤 논리적 작업을 수행해야 하는지 선언적으로 정의한다. Core API 보다는 로직을 표현할 수 있는 범위가 좁지만 UDF를 통해 어느정도 확장 가능하다. 또한 Spark DataFrame API처럼 실행되기 전 최적화 과정도 거친다.
테이블과 DataStream / DataSet 간의 변환이 가능하다.
4. SQL
Flink가 제공하는 최고 수준의 추상화로, streaming 및 batch 처리 로직을 SQL로 구현할 수 있다. Spark DataFrame과 Spark SQL의 관계와 마찬가지로 Table API 대신 SQL을 사용해 테이블을 조작할 수 있다. 로직을 SQL 형태로 구현해야 하기 때문에 표현 가능한 로직의 범위가 가장 좁을 수 밖에 없다.