나만의 데이터 카탈로그를 만들어보자 - Part. 1
데이터 카탈로그란?
데이터 카탈로그(Data Catalog)는 조직이 보유하고 있는 데이터를 체계적으로 정리하고 관리하는 데이터 플랫폼이다.
데이터베이스, 데이터 웨어하우스, 데이터 레이크 등 다양한 데이터 소스에서 메타데이터를 수집하여 사용자가 이를 쉽게 탐색하고 이해할 수 있도록 도와준다.
데이터 카탈로그는 일반적으로 다음과 같은 정보들을 제공한다.
- 데이터 소스 정보
- 데이터베이스 이름
- 커넥션 구성
- 테이블 정보
- 테이블 이름
- 테이블 설명
- 테이블 상태(생성 날짜, 마지막 업데이트 날짜)
- 테이블 오너
- 컬럼 정보
- 컬럼 이름
- 데이터 타입
- 컬럼 설명
- 컬럼 역할(primary key, partition key 등)
데이터 카탈로그의 장점
데이터 카탈로그는 다음과 같은 측면에서 데이터 거버넌스를 지원한다.
1. 데이터 탐색
조직이 보유한 데이터의 크기가 커질수록 필요한 데이터를 찾는 데 시간이 오래 걸린다. 데이터 카탈로그를 구축해두면 어느 팀이 어떤 데이터를 관리하고 있는지 빠르게 살펴볼 수 있다.
2. 데이터 품질 관리
데이터 카탈로그를 통해 데이터의 출처와 생애주기를 추적함으로써 데이터 생성, 처리, 저장 등 데이터 사용에 관한 가이드라인을 제공할 수 있다.
예를 들어 마지막 업데이트 날짜가 1년 전인 테이블이 있다면, 사용자는 해당 테이블을 의사 결정에 사용하는데 주의할 것이다.
3. 데이터 표준화
사람마다 용어를 이해하고 해석하는 방식이 다를 수도 있다. 데이터 카탈로그에 데이터가 무엇을 의미하는지 정확하게 기록해둠으로써 불필요한 혼란과 의사소통을 줄일 수 있다.
하지만
이러한 데이터 카탈로그를 이용해 데이터를 관리하는 것은 생각보다 어렵다. 실제로 겪었던 사례들을 바탕으로 데이터 카탈로그가 잘 정착하지 못했던 이유들을 정리해 보았다.
1. 데이터 소스의 복잡성
데이터 카탈로그가 필요할 정도의 조직은 관리해야할 데이터 원천의 개수도 매우 많다. 게다가 각 서비스 별로 사용되고 있는 데이터베이스의 성격도 다르기 때문에 한 군데로 통합하는 것이 생각보다 어려울 수 있다.
하지만 요즘엔 데이터 카탈로그 오픈소스들이 웬만한 데이터소스들은 대부분 지원하기 때문에 큰 걸림돌은 아니라고 생각한다.
2. 데이터 카탈로그 플랫폼의 부재
데이터 카탈로그 관리가 중요하다고 생각하더라도 자동화 플랫폼이 없는 경우가 있다.
- 데이터 분석가들이 엑셀로 데이터 카탈로그를 관리
- Notion이나 Confluence와 같은 wiki에 데이터 카탈로그 업데이트
ROI를 요구하는 경영진
이런 경우는 데이터 소스에서 변경이 발생할 때마다 사람이 직접 고쳐주어야 하기 때문에 굉장히 노동 집약적이다. 또한 일부 사용자들만 접근 가능하므로 나머지 조직 구성원이 데이터 카탈로그가 관리되고 있다는 사실 조차도 모를 수 있다.
3. 구성원 참여 부족
데이터 카탈로그 플랫폼을 구축하고 데이터 소스를 모두 연결했더라도 마지막 고비가 남아있다. 바로 구성원들의 참여도이다.
- 문서화가 귀찮은 데이터 오너
- Excel이 편하다는 상사
- 접근하기 어려울 정도로 과도한 권한 관리
데이터 카탈로그 만들어보기
사실대로 밝히자면 이번 글의 원래 목적은 데이터 카탈로그를 직접 구현해보는 것이었다.
지난 3분기 동안 회사에서 Text-to-SQL 프로젝트를 진행하면서 데이터 카탈로그 관리의 중요성을 많이 느꼈다. 어플리케이션을 개발하는 것보다 남들이 미뤄둔 데이터 카탈로그 작업을 대신 쳐내는데에 시간을 더 쏟았던 것 같다.
또 돌이켜보면 데이터 엔지니어 업무를 하면서 데이터 카탈로그를 볼 일이 많았다. 특히 Data Ingestion 작업을 할 때는 데이터 카탈로그만 보고 Scala 코드를 알아서 작성해주는 자동화 도구도 만들었었다.
따라서 이번 기회에 사이드 프로젝트로는 데이터 카탈로그를 만들어보고 지속적으로 기능을 추가해가면 재밌겠다는 생각이 들었다.
Blue Print
현재 개발하고 있거나 할 예정인 기능은 다음과 같다.
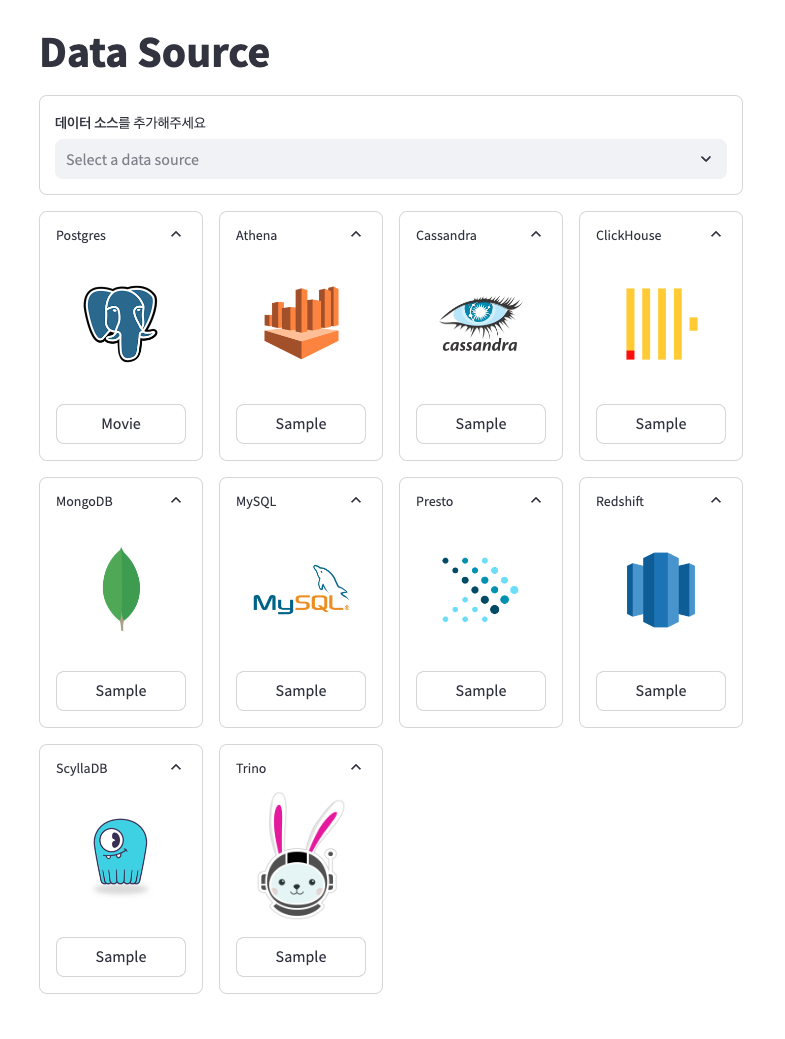
1. 데이터 소스 추가 + 커넥션 관리 도구
Redash, Airbyte, Datahub 등 많은 데이터 플랫폼에서 등장하는 패턴이다. 사용자가 데이터 소스에 대한 커넥션 구성을 등록하면 스키마와 테이블 리스트를 불러온다.
아직 프론트가 서툴기 때문에 streamlit을 이용해 빠르게 프로토타이핑하고 가능하다면 TypeScript로 넘어갈 예정이다.
2. 데이터 카탈로그 편집 기능
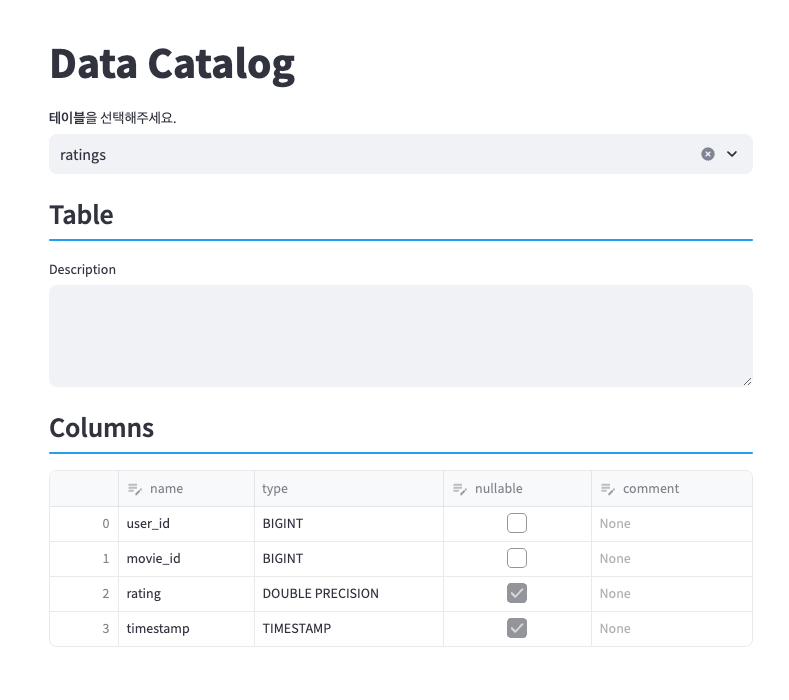
테이블 및 컬럼 Description을 적어 넣을 수 있도록 구현해야 한다. 영속성이 필요한 기능이기 때문에 Session State로 구현한 부분을 Postgres로 이관할 예정이다.
3. 스케쥴러
Airbyte에 대해 공부하면서 Temporal이라는 스케쥴링 프레임워크를 알게되었다. 이를 활용해 데이터 소스의 변경을 주기적으로 감지하여 데이터 카탈로그를 업데이트하는 기능을 구현할 예정이다.
4. 데이터 검색 기능
이 부분은 Sentence Transformer을 사용해 구현해 볼 예정이다.
5. Text-to-SQL
ChatGPT 또는 Claude API 키를 등록하면 데이터 카탈로그를 이용해 SQL 쿼리를 생성해주는 기능을 추가할 예정이다.