DBT 굉장하다
DBT
DBT란 Data Build Tool의 약자로, 데이터 처리에 필요한 코드를 모듈화하고 데이터의 품질 관리를 돕는 워크플로우 도구이다. 일단 분석 환경으로 데이터가 Ingestion 되고 나면, 데이터 분석가들은 이로부터 유의미한 비지니스 지표를 뽑아 내기 위해 대단히 많은 쿼리를 생성하고 실행하게 된다. 이때 분석가들이 엔지니어 도움 없이도 쉽게(?) 분석 결과를 테이블로 생성할 수 있도록 하는 것이 DBT의 목표라고 한다. 아니 해보니까 어렵던데
DBT를 이용하면 매번 반복되는 DML과 DDL를 작성할 필요 없이 재사용 가능한 SQL들을 생성하고 문서로 관리할 수 있다. 또 의존 관계를 정의하고 시각화 할 수 있어 어려운 비지니스 로직을 작성하더라도 실수할 여지를 줄일 수 있다. 마지막으로 버저닝 및 환경 분리를 위한 프로파일을 지원하고 있어 프로덕션에 배포하기 전에 비지니스 로직과 데이터 품질을 테스트해 볼 수 있다.
대략 2년 전 쯤 지인을 통해 처음 알게 되었는데, 최근 들어 많은 회사에서 도입하고 있다는 소식을 듣고 공부를 시작하였다. 직접 작업을 해보면서 느꼈던 DBT의 장단점들과 해볼만한 고민들을 이 글을 통해 공유하고자 한다.
참고로 DBT는 Cloud 서비스 뿐만 아니라 Github의 오픈소스로도 공개되어 있다.
Concept
Profiles
가장 먼저 profiles.yml 파일에 대한 이해가 필요하다. 이 파일에는 쿼리를 실행시킬 데이터 소스를 개발 환경 별로 정의할 수 있다. dbt init 커맨드로 생성한 경우에는 Mac 기준으로 ~/.dbt 디렉토리 아래에 위치해 있다. 환경 변수나 argument를 주입하여 다른 디렉토리로 위치시켜 사용 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
trino:
target: dev
outputs:
dev:
type: trino
host: trino-dev
port: 543
user: admin
password:
catalog: hive
schema: default
prod:
type: trino
host: trino-prod
port: 543
user: admin
password:
catalog: hive
schema: default
- 가장 상단의 “trino”는 프로필의 이름이다. DBT docs에서는 조직 이름을 사용하기를 권장하고 있다.
- “target”은 쿼리를 실행시킬 때 디폴트로 사용할 환경이다. 예시에서는 “outputs” 아래의 [“dev”, “prod”] 중 하나가 돼야 한다.
- “outputs”는 데이터 소스의 config이다. 예시와 달리 상황에 맞게 다른 이름을 사용해도 된다. (ex: “local”, “staging” 등)
Projects
다음은 dbt_project.yml 파일을 살펴보자. 이 파일에서는 DBT를 통해 실행시키고자 하는 Resource들의 경로와 설정들을 선언할 수 있다. 만약 dbt init 커맨드로 생성한 경우에는 다음과 같은 디렉토리 구조가 제공된다.
1
2
3
4
5
6
7
8
9
10
11
12
dbt_airflow
├── analyses
├── tests
├── seeds
├── macros
├── snapshots
├── models
│ └── dev
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
└── dbt_project.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 1
name: "dbt_airflow"
version: "1.0.0"
config-version: 2
require-dbt-version: [ ">=1.7.1", "<=1.7.7" ]
# 2
profile: "trino"
# 3
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
# 4
models:
dbt_airflow:
+on_table_exists: drop
dev:
+materialized: table
seeds:
dbt_airflow:
+full_refresh: true
- DBT 프로젝트 이름 및 버전
- 프로젝트에서 사용할 프로파일 이름
- 프로젝트가 가리키는 리소스들의 파일 경로
- 리소스 별 config 또는 property
Resources
Seed
해당 경로 아래에 있는 CSV 파일들을 등록된 데이터 소스로 업로드 한다. 뜯어보면 데이터를 청크로 나누어 동기적으로 Insert를 날리고 있기 때문에 데이터의 크기가 조금만 커도 굉장히 오래 걸린다. 때문에 운영 환경에서는 사용하지 않는 것이 좋아보인다.
청크의 크기가 1000개인지 세어봤다 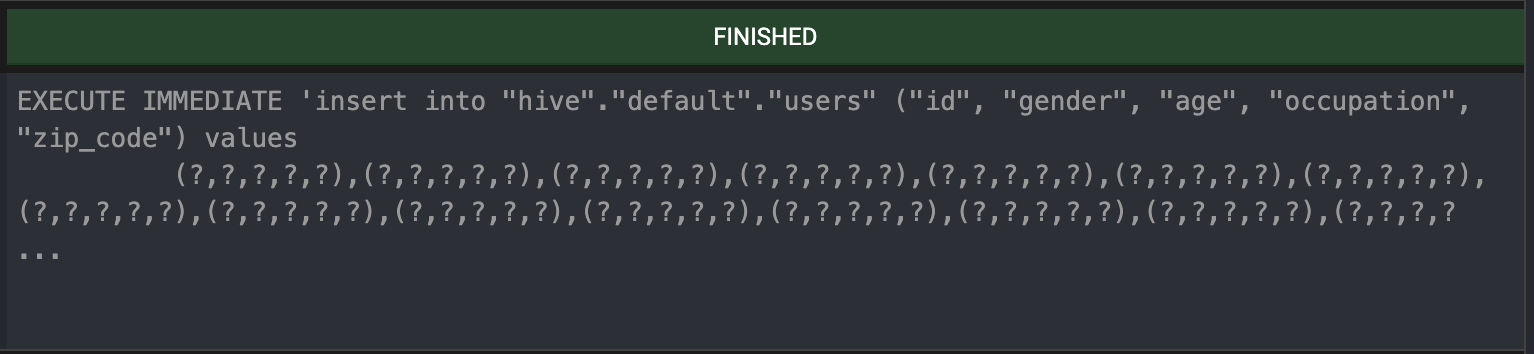
Model
DBT로 처리할 테이블들을 정의하는 곳이다. 테이블을 생성하기 위한 SQL을 jinja template과 함께 선언할 수 있다. 여기에는 데이터 소스에서 쿼리 결과를 어떠한 유형으로 저장할지 결정하는 Materialization 이라는 개념이 존재한다.
DBT Materialization에는 총 5가지의 유형이 있다.
table
- SQL 실행 결과를 테이블로 저장하여 데이터가 스토리지에 물리적으로 적재되도록 실행
view
- SQL을 View로 저장하여 조회 시 저장된 SQL을 실행
ephemeral
- SQL을 CTE로 저장하여 재사용 가능한 형태로 운영
incremental
- 새로 추가되거나 업데이트된 데이터를 테이블에 반영
materialized_view (dynamic_table)
- SQL을 View로 저장하고 실행 결과 데이터를 물리적으로도 저장
- 원본 테이블의 변경이 감지되면 SQL을 재실행하여 View를 새로고침하거나 변경분을 View에 반영
Snapshot
테이블의 변경 사항을 history 형태로 남기고 싶을 때 사용한다. 테이블이 SCD(Slowly Changing Dimension)인 경우에 유용하며, 데이터의 추가나 수정이 언제 발생했는지 알 수 있도록 dbt_valid_from과 dbt_valid_to 라는 두 컬럼이 붙은 새로운 테이블을 생성해 준다.
Macro
jinja template으로 UDF(User Defined Function)을 만들 수 있다.
Analysis
테이블을 실제로 생성하진 않지만, dbt compile 커맨드를 통해 모델을 실행 가능한 SQL 형태로 바꿔주는 역할을 한다.
Test
생략
Practice
다음 Github 링크에 설정들을 상세하게 정리해 두었습니다.
도커를 이용해 다음과 같은 환경을 띄워보려 한다. 데이터 소스로는 이전 글 Trino-Gateway 에서 소개한 Trino를 사용하였고, 워크플로우로는 흔히들 사용하는 Apache Airflow를 사용하였다.
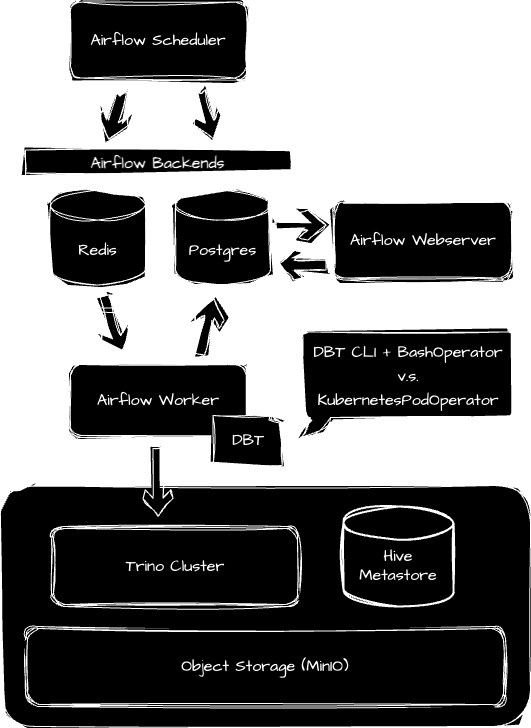
1. Trino
이번 Trino는 클러스터 형태로 사용할 필요는 없으므로 하나의 컨테이너만 사용하기로 한다. config.properties 파일에서 node-scheduler.include-coordinator=true로 설정해주면 coordinator를 worker로도 사용 가능하다. 너무 무겁다고 생각되면 Hive Metastore나 MinIO를 빼버려도 좋다. 지난번과는 다르게 Airflow와의 겹침을 방지하기 위해서 543 Port를 사용하였다.
1
2
3
4
5
6
7
8
9
10
11
12
trino:
container_name: trino
hostname: trino
image: trinodb/trino:435
ports:
- "543:543"
volumes:
- ./docker/trino/etc:/etc/trino
- ./docker/trino/catalog:/etc/trino/catalog
depends_on:
hive-metastore:
condition: service_healthy
2. Airflow
Airflow는 오픈소스에서 제공하는 yaml 파일을 사용하였다. 우리는 Airflow Worker에서 DBT CLI를 실행시킬 예정이므로 (1)과 같이 DBT와 관련된 파이썬 디펜던시를 설치해줘야 한다.
선언한 모델을 Airflow가 사용할 수 있도록 (2)와 같이 dbt project가 위치한 경로를 volumne에 mount 해준다. 아래 yaml파일과 달리 airflow-worker의 volume에만 추가해주어도 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
x-airflow-common: &airflow-common
image: apache/airflow:2.8.1-python3.9
environment: &airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'false'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: 'true'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: false
AIRFLOW__WEBSERVER__DEFAULT_UI_TIMEZONE: Asia/Seoul
AIRFLOW__CORE__DEFAULT_TIMEZONE: Asia/Seoul
AIRFLOW_UID: '50000'
_AIRFLOW_WWW_USER_USERNAME: airflow
_AIRFLOW_WWW_USER_PASSWORD: airflow
_PIP_ADDITIONAL_REQUIREMENTS: dbt-core==1.7.7 dbt-trino==1.7.1 # (1)
volumes:
- ./docker/airflow/dags:/opt/airflow/dags
- ./docker/airflow/config:/opt/airflow/config
- ./docker/airflow/plugins:/opt/airflow/plugins
- ./docker/airflow/logs:/opt/airflow/logs
- ./docker/dbt/dbt_airflow:/opt/airflow/dbts # (2)
현업에서는 이러한 디펜던시 설치가 까다로울 수 있다. 그럴 때는 별도의 이미지에 디펜던시를 분리하여 KubernetesPodOperator를 통해 다른 Pod에서 dbt를 실행시켜주면 된다. 하지만 DBT는 단순히 쿼리를 실행시키고 기다리기 때문에, 많은 컴퓨팅 리소스를 필요로하지 않으므로 이러한 방법은 개발 리소스나 비용 측면에서 오버헤드를 발생시킨다.
3. DBT
Docker compose 명령어를 실행시킨 후 Airflow Webserver가 위치한 http://localhost:8080으로 접속하면, 다음과 같은 워크플로우를 확인할 수 있다.

load_data
먼저 MovieLens에서 CSV 데이터를 dbts/seeds 경로에 다운로드 받는다.
1
2
3
4
5
load_data = PythonOperator(
task_id="load_data",
python_callable=download_data,
op_kwargs={"dir": "/opt/airflow/dbts/seeds"},
)
dbt_seed
다운로드 받은 CSV 데이터를 Trino로 업로드한다. 환경 변수 DBT_PROFILES_DIR에 profiles.yaml 파일이 위치한 경로를 주입하면 원하는 위치에서 dbt cli를 실행시킬 수 있다.
1
2
3
4
5
6
7
dbt_seed = BashOperator(
task_id="dbt_seed",
env={"DBT_PROFILES_DIR": "/opt/airflow/dbts"},
append_env=True,
bash_command="dbt seed",
cwd="/opt/airflow/dbts",
)
dbt_run
models 경로에서 선언해둔 모델들을 실행시켜 테이블을 생성한다.
1
2
3
4
5
6
7
dbt_run = BashOperator(
task_id="dbt_run",
env={"DBT_PROFILES_DIR": "/opt/airflow/dbts"},
append_env=True,
bash_command="dbt run",
cwd="/opt/airflow/dbts",
)
예를 들어 models 경로 아래에 recent_movies.sql 파일을 다음과 같이 두어 테이블을 생성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
{{ config(materialized="table") }}
WITH source_data AS (
SELECT *
FROM {{ ref("movies") }}
ORDER BY year DESC, id DESC
LIMIT 100
)
SELECT *
FROM source_data
dbt_test
seeds 또는 models 에서 정의된 데이터를 테스트한다.
1
2
3
4
5
6
7
dbt_test = BashOperator(
task_id="dbt_test",
env={"DBT_PROFILES_DIR": "/opt/airflow/dbts"},
append_env=True,
bash_command="dbt test",
cwd="/opt/airflow/dbts",
)
예를 들어 models 경로 아래에 schema.yaml 파일에서 테스트할 규칙을 선언할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
version: 2
models:
- name: recent_movies
description: "A starter dbt model"
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: title
- name: genres
- name: year
4. Result
DAG 실행이 끝나면 Trino에서 다음 쿼리를 실행시켜 테이블이 무사히 생성되었음을 확인할 수 있다.
1
2
3
SELECT *
FROM default.recent_movies
LIMIT 10;