Airbyte (2) - 근데 진짜 Ingestion 되는거 맞아요?
이전 글에서는 Airbyte가 무엇이고, 어떤 목적으로 사용되는지에 대해 다루어 보았다. Airbyte를 활용하면 다양한 소스로부터 데이터를 수집하고 최소한의 변환만을 수행한 뒤 목적지로 데이터를 전송하는 작업을 간소화할 수 있다.
이번 글에서는 Airbyte가 내부적으로 어떻게 동작하고 있는지 파악하기 위해 백엔드 아키텍처 구성을 살펴보고자 한다. 또, Helm을 이용해 Kubernetes 환경에서 Airbyte를 배포해보고 Connection을 생성하여 Data Ingestion 작업을 실습해 볼 예정이다.
Airbyte Architecture
MircroService Architecture
먼저 Airbyte는 확장성(Scalability)을 위해 백엔드로 마이크로서비스 아키텍처(MSA)를 채택하고 있는데, 그 이유를 생각해보면 다음과 같다.
1. Scalability
파이프라인들이 추가될수록 Worker와 Scheduler 등의 특정 서비스의 부하가 커질텐데, 이런 경우에 MSA는 필요한 서비스들을 독립적으로 확장하는데 유리하다.
2. Fault Isolation
장애가 발생하는 상황에 효과적이다. 특정 Connection이 응답 지연으로 인해 동작을 멈추더라도 다른 Connection의 Sync 작업에 영향이 없어야 한다. Airbyte는 이를 위해 다수의 Container과 이를 관리하는 Orchestrator를 두어 장애를 격리한다.
3. Flexibility Deployment
Airbyte에서 Connector들은 Docker Image로 저장되어 Worker의 Container로 실행되는데, MSA는 이러한 Connector들을 관리하기 용이하게 해준다. Marketplace에서 Connector를 불러오거나 Connector Builder를 통해 직접 Connector를 구현할 때, 서비스 중단 없이 Worker가 사용할 수 있도록 배포 가능하다.
Components
Airbyte에는 실제 Sync 작업을 수행하기 위해 데이터 처리를 담당하는 Worker와 이를 관리하는 API 서버, 데이터베이스 및 Scheduler 등이 주요 컴포넌트로 구성되어 있다.
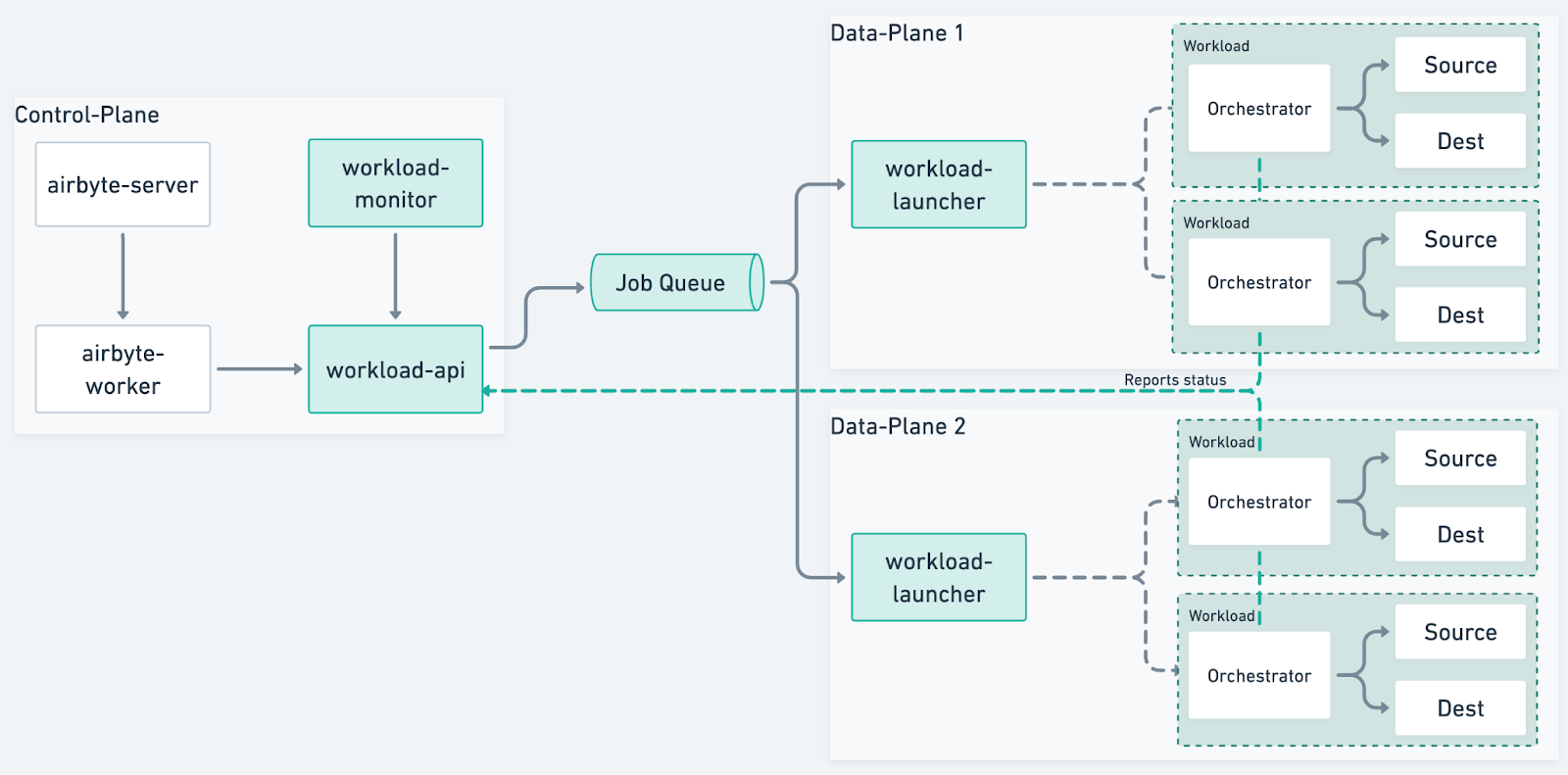
1. Web App/UI [airbyte-webapp]
Airbyte의 Web UI를 담당한다. 사용자들은 이곳에서 GUI를 이용해 Airbyte의 전반적인 기능들을 조작할 수 있다.

2. Config API Server [airbyte-server]
Airbyte의 control plane으로, Config와 Schedule 정보 관리를 책임진다.
사용자는 UI(혹은 API)를 통해 서버에게 Source, Destination 및 Connection 생성을 요청할 수 있으며, Config API Server는 이 요청을 토대로 Connection Config, 인증 정보, 스키마를 데이터베이스에 저장한다.
사용자가 새로운 Connection을 생성하고나면 Config API Server는 후술할 Temporal에게 Workflow를 생성하도록 요청한다. 만약 사용자가 Schedule Type(Scheduled/Cron)을 설정했다면, 서버는 Scheduler가 이 정보에 접근할 수 있도록 데이터베이스에 저장한다.
3. Database Config & Jobs [airbyte-db]
Airbyte의 백엔드 데이터베이스이다. 이곳에는 Connection을 생성할 때 사용했던 Config 및 Schedule 데이터가 저장된다. 또한 파이프라인이 실행될 때마다 Sheduler가 성공 여부, 실행 시간 등의 메타데이터를 수집하여 이곳에 저장한다.
4. Temporal Service [airbyte-temporal]
Temporal은 사실 Airbyte의 고유 컴포넌트가 아니라, 비동기 및 분산 처리 작업을 위한 오픈소스 Workflow 엔진이다.
Temporal는 작업이 실패하더라도 자동으로 복구 가능한(resilient) 처리 방식을 지향한다.
Temporal Service 속에는 Task의 비동기 처리를 위한 Queue, Workflow 실행을 위한 Worker, Workflow 정보를 저장하기 위한 데이터베이스가 독립적으로 구성되어 있다.
Workflow는 하나 이상의 Activity들로 구성되며 Worker들이 Queue로부터 Workflow를 하나씩 가져와 처리한다. Activity은 독립적인 실행 단위로, 실패하게 되면 Activity 단위로 재시도된다. 이 구조는 우리가 익히 알고 있는 Apache Airflow와 구조가 비슷하다.
| Airflow | Temporal |
|---|---|
| DAG | Workflow |
| Task | Activity |
Airbyte에서 Temporal Service의 역할은 Connection마다 Workflow를 생성하여 설정된 Schedule에 따라 Workflow을 실행하는 것이다. Workflow가 실행되면 Sync 작업(=Job)을 트리거 및 모니터링하고, 그 성공 여부에 따라 완료 처리 또는 재실행한다.
5. Worker [airbyte-worker]
앞서 언급한 것처럼 Temporal Service가 Workflow를 실행하면 Worker에서는 Job을 트리거한다.
Airbyte의 옛날 버전에서는 이 Worker에서 Sync 작업을 직접 처리했지만, 현재 1.0.0 버전 이상에서는 실제 데이터가 이동하는 data plane이 분리되면서 Worker에서 직접 Sync 작업을 하지 않게 되었다.
대신 Worker는 후술할 Workload API Server를 호출하여 Job을 생성한다.
6. Workload API Server [airbyte-workload-api-server]
Airbyte에서 Workload API Server는 Sync 작업과 관련된 전반적인 프로세스를 실행하고 모니터링하는 역할을 한다.
Worker로부터 API 호출이 들어오면 Workload API Server는 Job을 생성하여 Queue에 넣는다.
7. Workload Launcher [airbyte-workload-launcher]
Workload Launcher는 Workload API Server가 Queue에 넣은 Job을 읽고 Sync 작업에 필요한 컴퓨팅 자원을 K8S에 요청한다. (Queue를 이용한 일종의 Back Pressure)
Workload Launcher가 Job을 실행하면 Workload라는 Pod가 생성되어 Sync 작업을 시작한다. 이때 Workload 속에서는 3가지 Container가 실행된다.
- Source
- Orchestrator
- Destination
8. Other Components
- Minio [airbyte-minio]
- Logs storage를 담당한다.
- Helm은 기본값으로 minio를 사용하지만 AWS S3와 같은 외부 storage 사용을 권장한다
- Bootloader [airbyte-bootloader]
- Airbyte의 초기 세팅을 담당한다.
- Cron [airbyte-cron]
- 오래된 서버 로그와 Sync 작업 결과 로그를주기적으로 청소한다.
- Connector들을 주기적으로 업데이트한다.
- Pod sweeper [airbyte-pod-sweeper]
- Kubernetes에서 작업을 완료한 Pod들을 청소한다.
Airbyte on K8S
다음 Github 링크에 설정들을 정리해 두었습니다.
이제 Helm Chart를 통해 Kubernetes 환경에서 Airbyte를 배포해보자.
Kubernetes Setting
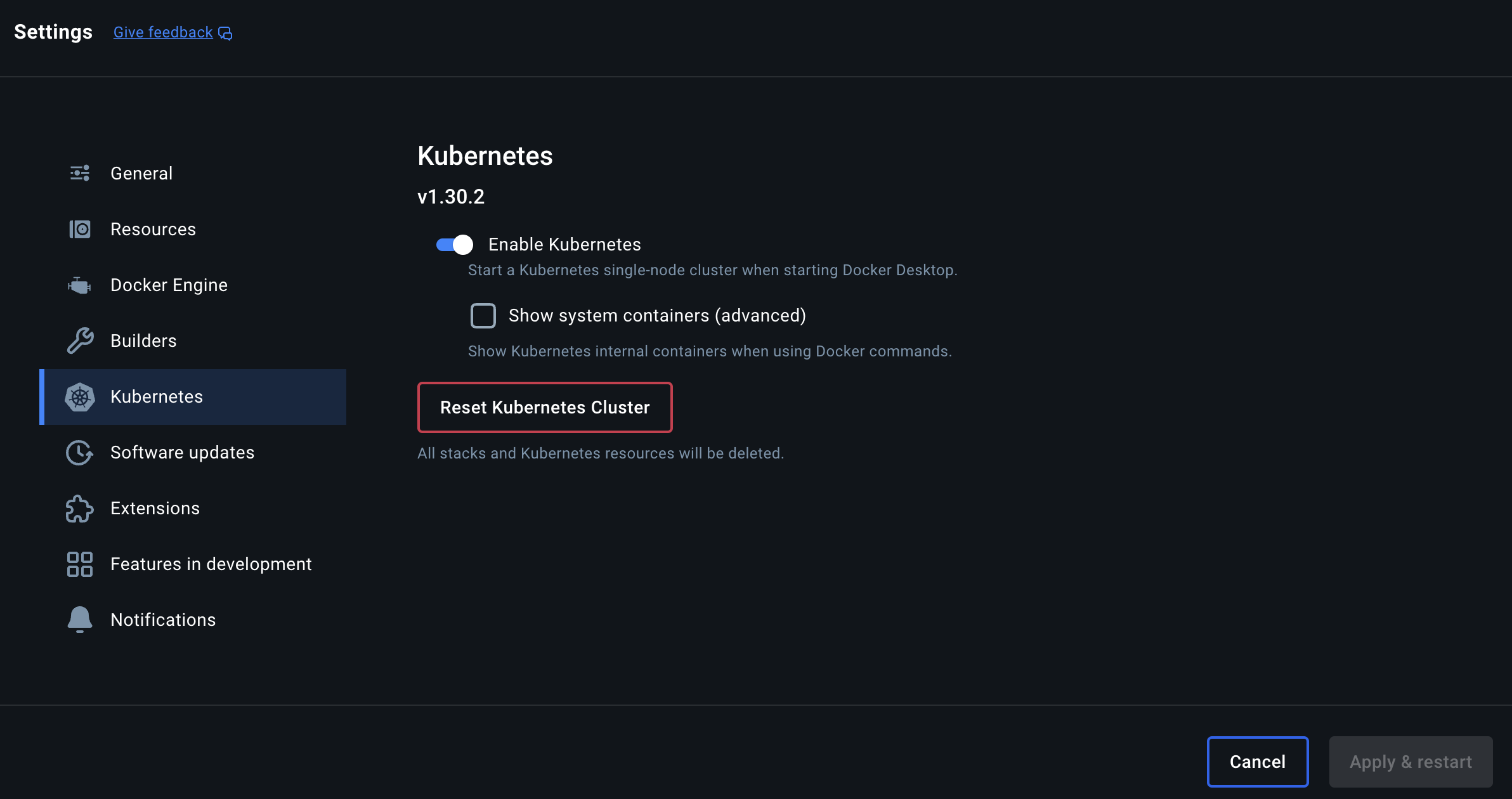
먼저 Docker Desktop을 사용하여 Kubernetes 환경을 세팅한다. Settings에서 Enable Kubernetes 토글을 활성화 하면 Kubernetes를 사용할 수 있다.
Kubernetes를 조작하기 위해서는 Kubectl이라는 command-line tool이 필요하다. Kubectl은 Brew를 이용해 간단히 설치할 수 있다.
1
brew install kubectl
Helm이라는 패키지 관리 도구를 이용하면 Airbyte를 좀 더 간편하게 배포할 수 있다. 마찬가지로 Brew를 이용해 Helm을 설치해주자.
1
brew install helm
Airbyte
Airbyte의 경우 이미 Helm Chart가 작성되어 있다. 이를 Helm Client에 추가해주자.
1
helm repo add airbyte https://airbytehq.github.io/helm-charts
이번 배포 작업에서는 airbyte라는 별도의 namespace를 만들어서 사용하기로 한다. 해당 namespace에서 Airbyte를 배포해보자.
1
2
3
kubectl create namespace airbyte
helm --namespace airbyte install airbyte-local airbyte/airbyte
Airbyte를 배포하고 Kubernetes Service 목록을 조회하면 위에서 설명했던 Airbyte 컴포넌트들을 확인할 수 있다.

Nginx
Kubernetes에 Airbyte를 배포했다면 이제 로컬에서 UI에 접근할 수 있도록 포트 포워딩해주어야 한다. 먼저 Helm으로 nginx ingress controller를 설치하자.
1
helm --namespace airbyte install airbyte-nginx oci://ghcr.io/nginxinc/charts/nginx-ingress
Port Forwarding
Local host로 접근 시 airbyte-webapp 서비스를 라우팅할 수 있도록 YAML 파일을 작성하고 Service에 등록한다. 그러면 http://localhost를 통해 UI에 접근할 수 있다.
[ingress/nginx.yaml]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: airbyte-ingress
annotations:
ingress.kubernetes.io/ssl-redirect: "false"
spec:
ingressClassName: nginx
rules:
- host: localhost
http:
paths:
- backend:
service:
name: airbyte-local-airbyte-webapp-svc
port:
number: 80
path: /
pathType: Prefix
1
kubectl --namespace airbyte apply -f ingress/nginx.yaml
Source & Destination on Docker
이제 Connection을 한번 생성해보자. 이번 실습에선 Source로 MySQL를, Destination으로 MinIO를 사용해보았다.
아래와 같이 Docker compose 용 YAML 파일을 작성하여 배포해보자. 이때 MinIO에서 hive 버킷을 생성하기 위해서 minio-client 서비스를 추가한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
services:
mysql:
container_name: mysql
hostname: mysql
image: mysql:8.0
ports:
- "3306:3306"
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
volumes:
- ./docker/volume/mysql:/var/lib/mysql
- ./docker/mysql/:/docker-entrypoint-initdb.d/
environment:
TZ: Asia/Seoul
MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD:-test}
MYSQL_USER: ${MYSQL_USER:-airbyte}
MYSQL_PASSWORD: ${MYSQL_PASSWORD:-airbyte}
MYSQL_DATABASE: ${MYSQL_DATABASE:-dev}
MYSQL_ALLOW_EMPTY_PASSWORD: true
minio:
container_name: minio
hostname: minio
image: minio/minio
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123
MINIO_DOMAIN: minio
command: server /data --console-address ":9001"
volumes:
- ./docker/volume/minio:/data
healthcheck:
test: "mc ready local"
interval: 10s
retries: 3
start_period: 5s
minio-client:
container_name: minio-client
hostname: minio-client
image: minio/mc
entrypoint: >
/bin/bash -c "
mc config --quiet host add storage http://minio:9000 minio minio123 || true;
mc mb --quiet --ignore-existing storage/hive || true;
"
environment:
AWS_ACCESS_KEY_ID: minio
AWS_SECRET_ACCESS_KEY: minio123
AWS_REGION: ap-northeast-2
AWS_DEFAULT_REGION: ap-northeast-2
S3_ENDPOINT: http://minio:9000
S3_PATH_STYLE_ACCESS: true
depends_on:
minio:
condition: service_healthy
또한 MySQL에서 Data Ingestion에 사용할 category 테이블을 생성하기 위해 다음 sql 파일을 docker-entrypoint-initdb.d 경로에 추가해주었다.
[init.sql]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
USE dev;
CREATE TABLE IF NOT EXISTS category (
id INT NOT NULL AUTO_INCREMENT,
category_name VARCHAR(20) NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO category (category_name) VALUES
('apparel'),
('food'),
('furniture'),
('grocery'),
('etc')
;
Connection
[Source]
이제 Source를 등록해보자. Kubernetes의 컨테이너에서 Localhost로 접근하는 케이스이므로, Host에는 host.docker.internal를 입력해준다.
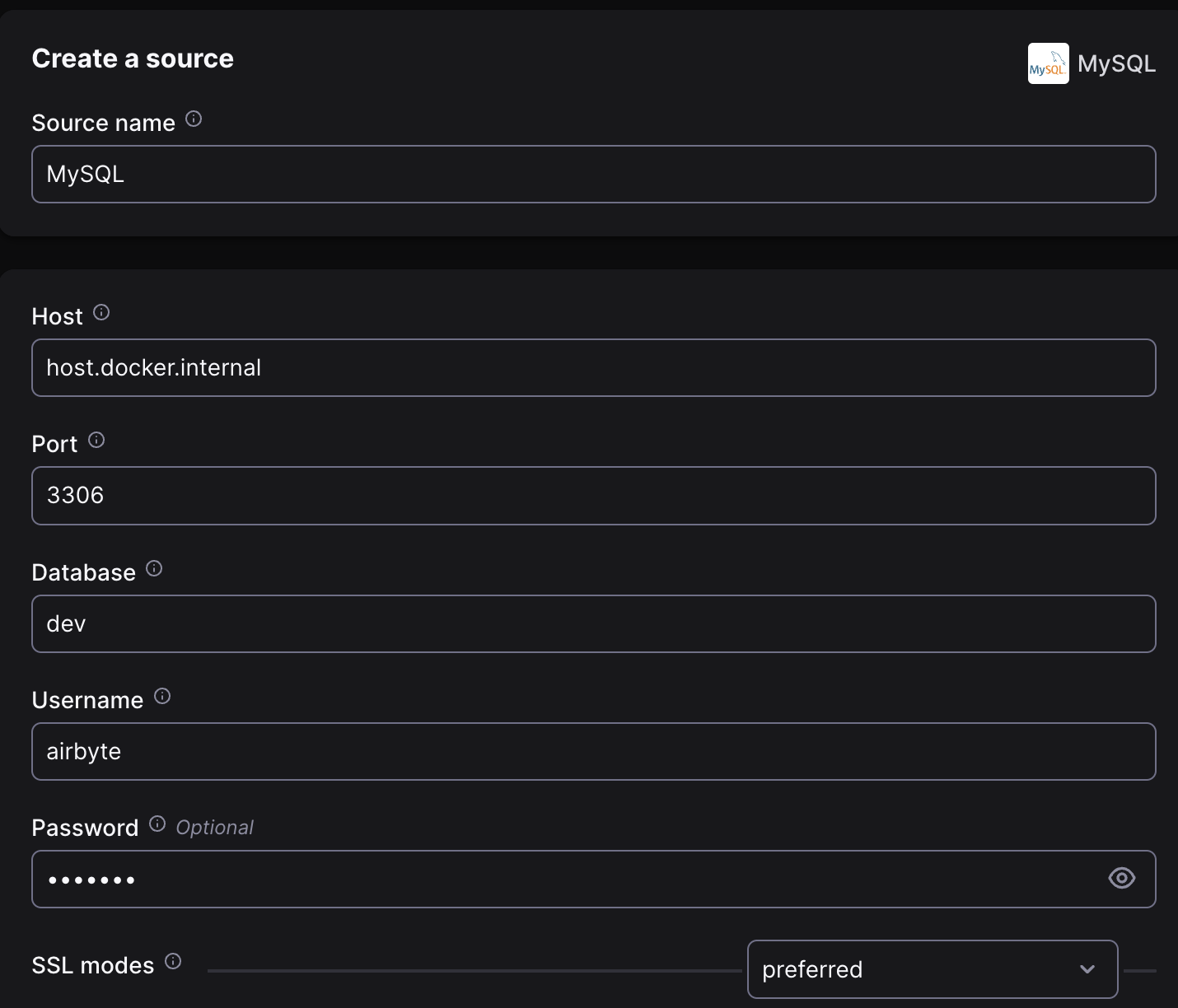
또는 별도의 External Name Service를 배포하여 Alias를 사용할 수 있다.
1
2
3
4
5
6
7
kind: Service
apiVersion: v1
metadata:
name: airbyte-external
spec:
type: ExternalName
externalName: host.docker.internal
[Destination]
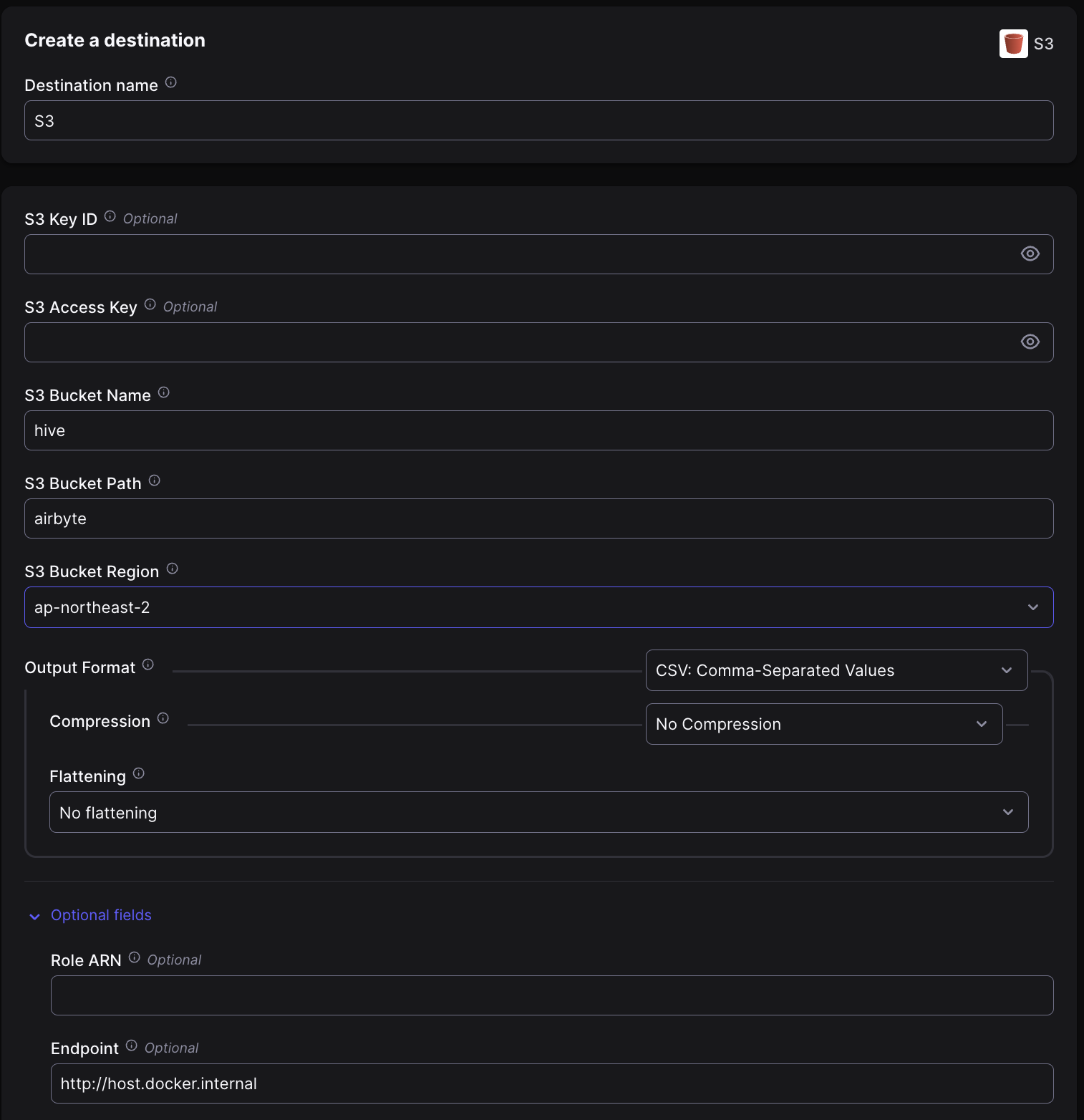
MinIO를 Destination으로 등록하기 위해서는 S3 Connector를 사용해야 한다. 이때 S3 Access Key는 MinIO 콘솔(localhost:9001)에서 생성하여 사용할 수 있다.
Source 때와 마찬가지로 Optional fields의 S3 Endpoint 항목에 http://host.docker.internal를 채워넣어주자.
Result
Source와 Destination 등록 후 Connection을 생성할 수 있다. 이때 Sync할 테이블 목록을 확인할 수 있으며, Schedule Type 등을 세팅할 수 있다.
Schedule Type을 Manual로 선택한 후 Connection 생성을 완료하면 Sync 가능한 Stream 목록을 볼 수 있다.
상단의 Sync Now 버튼을 클릭하면 MySQL의 category 테이블에서 MinIO의 hive 버킷으로 데이터 복제가 시작된다. MinIO 콘솔에 접속하면 복제된 데이터를 확인할 수 있다.
