Airbyte (1) - Data Ingestion, 그런데 이제 Airbyte를 곁들인
최근 많은 회사에서 Data Ingestion 도구 중 하나인 Airbyte를 도입하고 있다. 이번 글에서는 Data Ingestion과 Airbyte가 무엇인지 알아보고자 한다.
본론에 앞서, 혹시나 데이터 엔지니어링에 관심이 있는 분이라면 Airbyted의 공식 블로그를 한번 읽어보길 추천한다. 이곳에는 Airbyte 뿐만 아니라 데이터 엔지니어링과 관련된 다양한 내용들이 잘 정리되어 있다.
Data Ingestion
Data Ingestion이란, 다양한 소스로부터 데이터를 수집하여 이를 분석에 용이한 환경으로 적재하는 과정을 의미한다. 여기서 데이터 소스에는 MySQL과 같은 데이터베이스 및 파일 시스템, API 등이 있으며, 분석 환경은 데이터 웨어하우스와 데이터 레이크 등을 가리킨다.
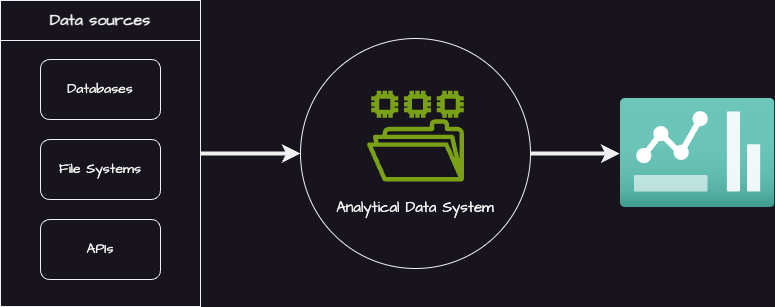
그렇다면 왜 Data Ingestion이 필요할까?
첫번째 이유로는 여러 곳에 나뉘어 있는 데이터를 한 곳으로 통합하여 데이터의 활용도를 높이기 위함이다. 예를 들어 상품 카테고리 별 클릭 수를 계산하기 위해서는 데이터베이스 속 상품 카테고리 정보와 파일 시스템 속 유저 클릭 로그를 동일한 환경에 위치시켜야 한다.
두번째로는 운영 환경과 분석 환경을 분리하기 위함이다. 만약 운영 환경에서 데이터 분석을 진행한다면, 서비스 이용자들과 읽기 자원을 공유하게 되면서 운영 환경에 부하를 일으킬 수 있다. 따라서 별도의 분석 환경을 구축하되, 데이터 분석에 최적화된 데이터 웨어하우스로 데이터를 복제하여 확장성을 확보하는 것이 필요하다.
Data Ingestion Types
Data Ingestion 방식에는 크게 두 가지 유형이 있다. 지금까지의 데이터 엔지니어링 경험을 보태어 각 방식에 따라 파이프라인 개발 시 어떠한 점들을 고려해야 할지 정리해 보았다.
| Batch Ingestion | Real-time Ingestion |
|---|---|
| 데이터를 묶어서(batch) 처리 | 실시간으로 데이터를 처리 |
| 주기적으로 정해진 시간에 실행 | 상시 혹은 연속적으로 실행 |
| 비용 효율적 | 비용이 비쌈 |
| 부하가 집중됨 | 부하가 분산됨 |
1. Batch Ingestion
Batch Ingestion 방식이라면 데이터 소스의 부하에 주의해야 한다. 서비스 이용이 활발한 시간을 되도록 피하여 읽기 자원을 너무 많이 차지하도록 해서는 안된다.
Batch Ingestion은 pull-based 모델이다. 따라서 application 개발 시에는 데이터의 양이 많을 수록 더 잘게 chunk를 쪼개어 네트워크 bandwidth에 병목이 발생하지 않도록 주의해야 한다. Chunk를 생성할 때도 skewness 및 lock을 걸지 않음으로써 발생할 수 있는 중복 데이터를 신경 써주어야 한다.
2. Real-time Ingestion
Real-time Ingestion 방식이라면 고가용성(High Availability)를 고려해야 한다. Application이 오랫동안 다운되면 데이터 누락이 발생할 수 있으므로 웬만하면 클러스터 단위로 운영해야 한다.
Real-time Ingestion은 push-based 모델이기 때문에 최종적으로 저장되는 파일의 크기가 작고 파일의 개수가 많다. 이는 낮은 읽기 성능을 초래할 수 있으므로 주기적인 file compaction 작업을 함께 구현해주는 것이 좋다.
Data Ingestion Patterns
아마 많은 데이터팀들이 각자의 방식으로 Data Ingestion 파이프라인들을 운영하고 있을 것이다. 데이터베이스의 테이블로부터 데이터 웨어하우스의 테이블로 덤프(dump)하는 상황을 가정해보면, 가장 흔하게 보이는 패턴들은 다음과 같을 것이다.
1. Full Load
Full Load는 정해둔 시각에 Batch Ingestion을 실행하여 테이블 속 모든 데이터를 복제하는 패턴이다.
이 방법은 테이블 구조나 데이터 적재 방식을 고려하지 않아도 되어서 매우 편리하다. 하지만 테이블의 크기가 클 수록 큰 비용과 부하가 발생한다. 따라서 보통은 하루에 한번, 새벽 시간 대에 해당 작업을 진행하게 된다.
Full Load 패턴의 가장 큰 단점은 멱등성(idempotency)이 보장되지 않는다는 것이다. 파이프라인의 실행 시점에 따라 소스 테이블의 데이터도 바뀌어 있기 때문에, 장애 복구 상황이나 백필 상황에서 이전과 동일한 결과를 얻기가 쉽지 않다. 이는 데이터 품질 검증을 까다롭게 하는 큰 요인이다.
2. Incremental Load
Incremental Load는 일정한 주기로 Batch Ingestion을 실행하되, 이전 Ingestion 작업 시점으로부터 변경이 일어난 데이터만 복제하여 원본에 병합하는 패턴이다.
이 패턴은 Full Load와 비교하여 매우 적은 데이터를 처리하므로, 데이터 소스에 가해지는 부하가 적다는 장점이 있다. 따라서 실행 주기를 줄여 데이터의 최신성을 높일 수 있다.
다만 이를 구현하기 위해서는 데이터 구조에 제약이 따른다. 변경분을 가져와야 하므로, modified_at과 같이 데이터의 업데이트를 감지할 수 있는 컬럼(cursor field)이 반드시 필요하다.
또 데이터 웨어하우스에서 중복을 제거해야 하는 경우엔 Primary Key가 명시되어야 하며, 이때는 OLAP의 특성으로 인해 full scan이 발생할 수 있기 때문에 아무리 실행 주기를 줄이더라도 실시간 처리 만큼의 최신성 확보는 어렵다.
Full Load와 마찬가지로 Incremental Load 패턴은 멱등성을 보장해주지는 못한다. 또, 데이터의 hard deletion에 대처가 불가능하다는 단점을 가진다. 따라서 soft deletion이 발생하는 테이블에만 적용하거나 Full Load를 적절히 섞어서 스케쥴하는 것이 좋다.
3. Change Data Capture (CDC)
CDC 패턴은 Real-time Ingestion 방식을 통해 데이터의 모든 변경 사항을 로그로 남긴다. Incremental Load 패턴과의 차이점은 원본과의 병합에 변경이 일어난 데이터가 아니라 변경 로그를 사용한다는 점이다.
덕분에 이 방법으로는 hard deletion에도 대처가 가능한데, Debeizum이나 DynamoDB Streams와 같은 도구들이 delete flag를 잘 지원해주기 때문이다.
또 모든 업데이트 이벤트들을 로그로 남기기 때문에 멱등성을 보장할 수 있다. End-of-date 기준으로 로그를 필터링한 후 병합하면 다른 데이터들과의 정합성 문제를 해결할 수 있다.
다만 CDC 패턴을 도입하고 싶다면, 고가용성이나 장애 복구를 위해 어느 정도의 비용과 고생을 각오해야만 한다.
Airbyte
Airbyte란 Data Ingestion을 위한 도구 중 하나이다. 공식 홈페이지에서는 Airbyte를 다음과 같이 소개하고 있다.
Airbyte is an open-source data integration engine that helps you consolidate your data in your data warehouses, lakes and databases.
Airbyte의 가장 큰 특징은 위에서 설명한 Data Ingestion의 개념과 패턴을 정리하여 제품화했다는 점이다. 이게 무슨 얘기인지는 Airbyte 공식 문서 속 개념들을 통해 알아보자.
Airbyte Concepts
1. Source
Airbyte에서의 Source는 말 그대로 복제할 데이터의 소스를 의미한다. MySQL, Postgres와 같은 데이터베이스 뿐만 아니라, MongoDB 등의 NoSQL, AWS S3 등의 클라우드 스토리지 및 각종 3rd party API들을 Connector로 지원하고 있다. 각 Connector에 맞게 configuration 세팅을 마치고나면 Airbyte에 Source로 등록이 되어 재사용이 가능하다.
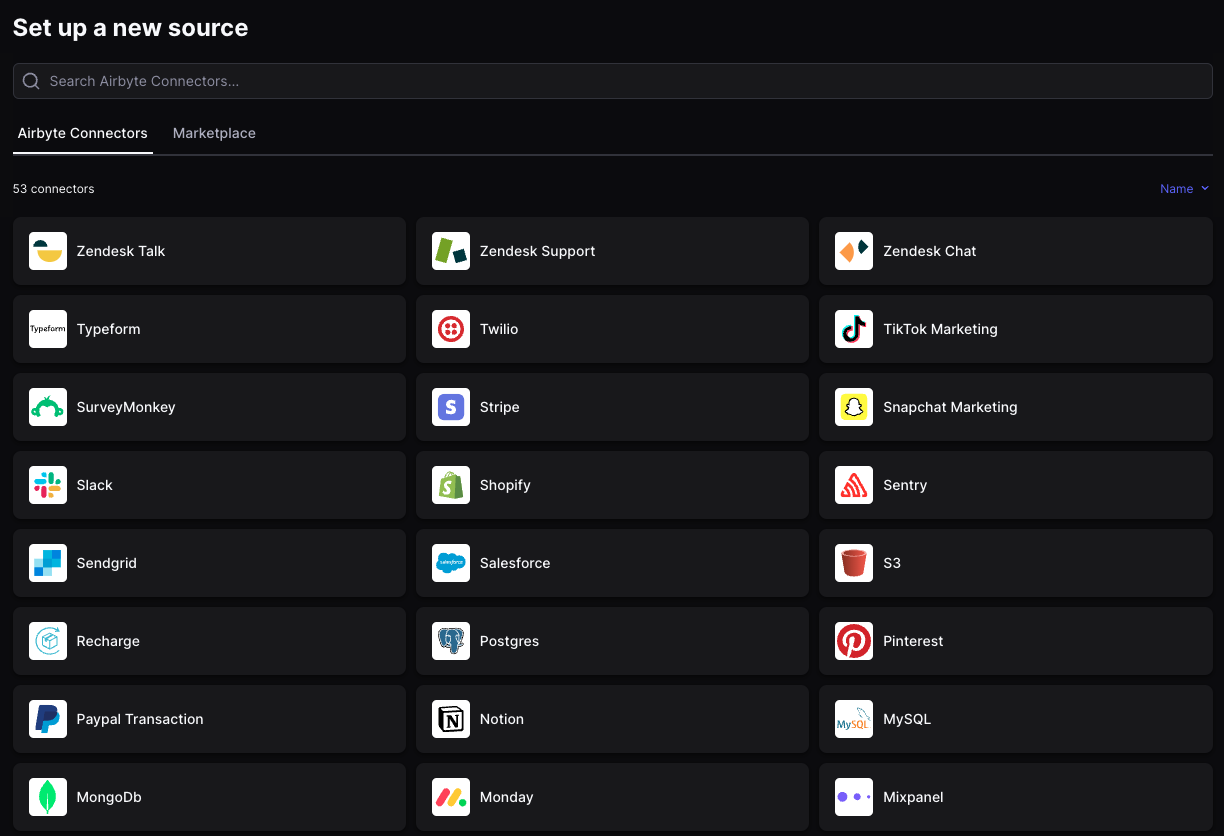
2. Destination
Airbyte에서의 Destination은 복제된 데이터를 적재할 목적지를 가리킨다. 현재 Redshift, Bigquery 등의 데이터 웨어하우스와 Milvus, Pinecone 등의 벡터 데이터베이스를 Connector로 지원하고 있다.

3. Connector
미리 한번 언급되었지만, Connector는 Source 또는 Destination의 동작에 필요한 플러그인이다. 예를 들어 MySQL 플러그인을 선택한 후 접근을 위한 credential 세팅을 마쳐야 하나의 MySQL Source가 생성된다. (Connector-Source/Destination의 관계를 Class-Instance의 관계로 봐도 좋을 것 같다.)
4. Connection
Airbyte에서 Connection은 Source와 Destination을 조합하여 만드는 파이프라인을 의미한다. 이때 단순히 Source와 Destination을 선택하는 것 뿐만 아니라
- 어떤 컬럼을 복제할지
- 어떤 패턴으로 복제할지
- 언제, 얼마나 자주 복제할지
등을 결정할 수 있다.
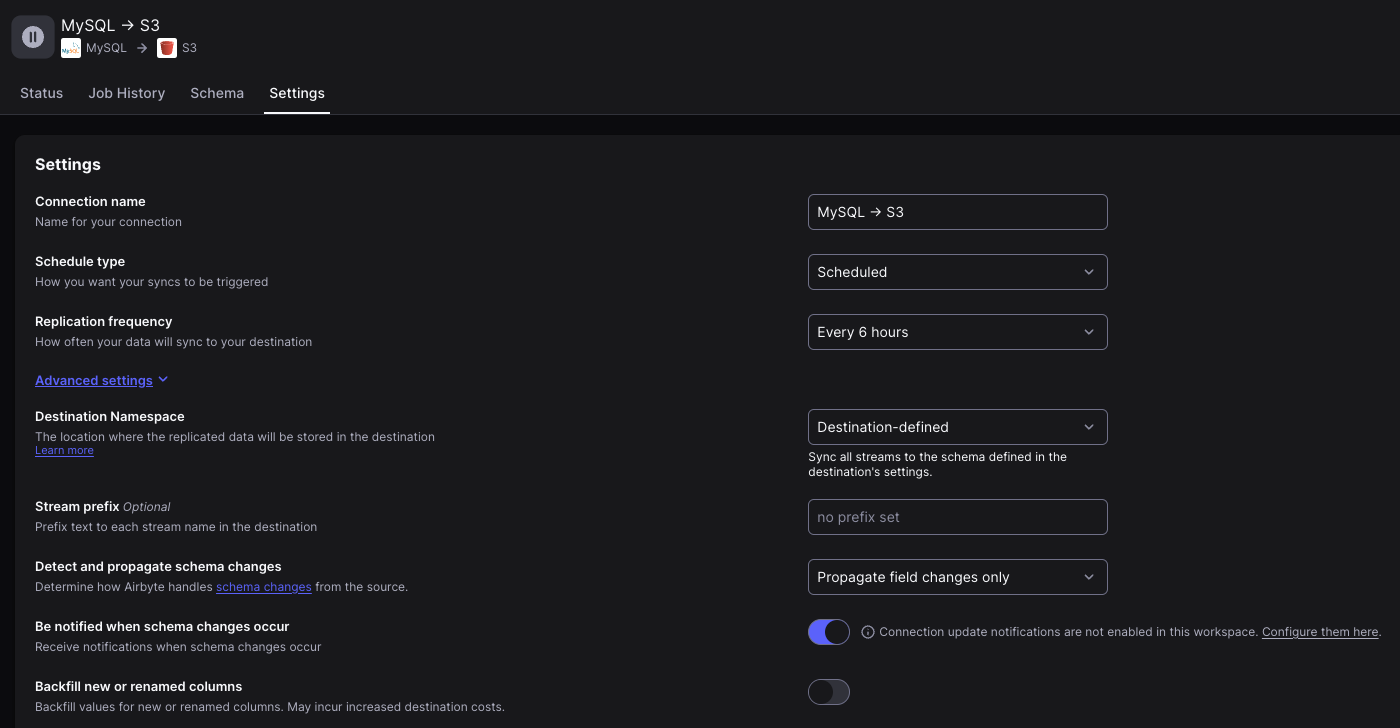
5. Stream, Record, Field
Airbyte는 다양한 유형의 데이터 소스를 지원하다 보니, 데이터베이스의 용어인 (Table / Row / Column) 대신에 (Stream / Record / Field) 이란 용어를 사용하고 있다.
| Terms | Stream | Record | Field |
|---|---|---|---|
| Database | table | row | column |
| API | endpoint | json unit | field |
| File system | file | line in a file | - |
6. Sync Mode
Airbyte에서는 데이터 동기화 방식을 선택할 수 있다. 위에서 설명한 Data Ingestion 패턴들이 그대로 구현되어 있다.
Source part
1
2
3
4
1. Incremental
Method 1 - Cursor field를 사용하여 변경이 일어난 데이터만 읽어온다.
Method 2 - CDC를 이용해 데이터의 변경 로그를 읽어온다.
2. Full Refresh - 모든 데이터를 읽어온다.
Destination part
1
2
3
4
1. Overwrite - 읽어온 데이터를 덮어 쓴다.
2. Append - 읽어온 데이터를 추가한다.
3. Append Deduped - 읽어온 데이터를 추가한 후, primary key를 이용해 중복 제거 한다.
4. Overwrite Deduped - 읽어온 데이터를 덮어 쓴 후, primary key를 이용해 중복 제거 한다.
이에 따라 가능한 조합은 다음과 같다.
| Option | Best Practice |
|---|---|
| Incremental Append | 로그 데이터인 경우 |
| Incremental Append + Deduped | 테이블을 동기화하는 경우 |
| Full Refresh Append | 테이블의 스냅샷을 뜨는 경우 |
| Full Refresh Overwrite | 테이블의 크기가 작은 경우 |
| Full Refresh Overwrite + Deduped | 소스에서 데이터를 읽어 올때 중복이 발생하는 경우 |
7. Sync Schedule
Airbyte에서는 Airflow 처럼 동기화 시간을 설정해 줄 수 있다.
1
2
3
1. Scheduled - 주기 설정 가능 (ex: 24시간, 2시간, 1시간 마다)
2. CRON schedule - Cron Expression을 사용하여 실행 시각 설정 가능
3. Manual - 버튼을 눌러 직접 실행 가능
8. Resumability
Airbyte는 v1.0.0 버전부터 Resumable Full Refresh를 지원하고 있다. 이 기능은 Full Refresh 작업이 실행되는 중 에러가 발생했을 때 테이블 전체를 다시 읽어야 하는 문제를 완화해준다. 자세한 내용은 다음 공식 문서를 참고하도록 하자.
Data Mesh
개인적으로 Airbyte는 Data Mesh라는 패러다임과 잘 어울리는 오픈소스라고 생각한다. 그 이유는 다음과 같이 데이터 탈중앙화(=데이터 엔지니어의 실직)를 가능케하고 있기 때문이다.
1. Domain-Oriented Data Ownership
우리가 보고 싶은 데이터가 운영 환경의 MySQL에 있다고 가정해보자. 이를 분석 환경으로 가져와 데이터 분석을 하기 위해서는 데이터베이스 속 데이터를 분석용 데이터베이스로 이관하는 작업, 즉 Data Ingestion이 필요하다.
기존에는 이러한 파이프라인을 개발하는 작업을 중앙 데이터 조직의 엔지니어가 수행함으로써 데이터 공급자(도메인팀 DB 관리자)와 데이터 소비자(데이터 분석가) 사이에 브로커가 불필요하게 끼어 있는 형태였다.
하지만 만약 Airbyte를 사용한다면 데이터 공급자가 직접 자신의 팀이 필요로 하는 테이블을 Airbyte에 등록 혹은 제외하면 되므로, 도메인팀이 분석 환경에 데이터를 제공하는 오너십을 가질 수 있다.
2. Self-Serve Data Platform
우리가 보고 싶은 데이터가 모두 위처럼 MySQL에 있다면 좋겠지만 현업에서는 그렇지 않다. DynamoDB나 Cassandra와 같은 NoSQL에 있을 수도 있고, Zendesk나 Google Ads로부터 API를 통해 받아와야할 수도 있다. 심지어 Google Sheet나 SharePoint 처럼 사람에 의해 메뉴얼하게 관리되는 데이터를 가져와야할 때도 있다.
원래라면 이렇게 다양한 데이터 소스들에 대처하기 위해서 데이터 엔지니어가 각 데이터 소스에 맞게 Ingestion 및 Scheduling 전략을 세우고 코드를 작성해야 했다. 하지만 Airbyte를 사용한다면 별 다른 데이터 엔지니어링 지식 없이도 누군가 만들어 놓은 Connector를 이용해 파이프라인을 쉽게 생성할 수 있다.
Next Step
다음 글에서는 Airbyte의 아키텍처를 살펴보고, Docker를 이용해 직접 띄워보는 작업을 다뤄 볼 예정이다!